Objetivos
El objetivo de este tema será acceder al contenido de los ficheros, bien para leer únicamente o bien para guardar información de forma permanente.
Para ello en Java disponemos de las clases de flujo de datos (streams). Lamentablemente Java dispone de una cantidad de streams extraordinariamente grande, lo que supone una gran complejidad para el programador (ya que debe recordar muchas clases). Por el contrario ofrece una potencialidad muy grande.
Dada esta variedad de clases y la complejidad inherente, este tema comenzará el tratamiento del contenido de los ficheros separando las clases en 2 categorías: considerando la información como un conjunto de bytes, y considerándola como un conjunto de caracteres.
En el siguiente tema se continuará, viendo formatos especiales de ficheros y también diferentes maneras de acceder.
1 Almacenes y flujos de datos
En la mayor parte de programas necesitamos guardar información de forma permanente, de manera que perduren, aunque finalice la ejecución del programa, o que sirvan de datos iniciales. Los ficheros nos proporcionan la forma más sencilla de guardar información.
En el tema anterior vimos como poder acceder tanto a un directorio como un archivo, pero no accedimos al contenido de los mismos. De los archivos sólo podíamos ver sus características externas: nombre, tipo, permisos, tamaño, … Pero en ningún momento acceder a su contenido. Será lo que veremos en este tema.
En un archivo, como decíamos, quedará guardada la información de forma permanente. Será una secuencia de bits, uno detrás del otro que representarán los datos guardados, bien sean caracteres de un texto, datos numéricos, o los bytes de una imagen, por ejemplo. Esta secuencia de bits nos aporta una visión estática de los datos, ya que quedan guardadas a lo largo del tiempo.
Poniendo un ejemplo clásico, los pantanos y depósitos donde se almacena el agua serían comparables a los ficheros. Pero para nosotros estos pantanos y depósitos quedan lejos. Y cuando hablamos de agua corriente tenemos más tendencia a pensar en las tuberías y grifos que nos llevan esta agua almacenada hasta nosotros. Pues de forma similar, desde el punto de vista de la aplicación, lo que realmente cobra importancia es la transferencia de datos, más que el almacén, que le llegan estos datos o que las pueda transferir hasta el fichero. La herramienta que nos permite controlar estas transferencias, de forma similar a los grifos y tuberías, la llamamos flujo de datos. Es un concepto asociado a la transmisión secuencial de una serie de datos desde la aplicación en el dispositivo de almacenamiento o al revés. Nos da una visión eminentemente dinámica de la información.
Java utiliza los streams (flujos de datos) para poder acceder a la información. Pero no se limita a la información de un archivo, sino desde cualquier fuente de datos: memoria, red, incluso otras aplicaciones. De esta manera se generaliza el acceso a la información desde cualquier procedencia: si conectamos un stream a un fichero, estaremos accediendo a un archivo, pero si conectamos el stream a otro programa estaremos accediendo a los datos proporcionados por otro programa. Intentaremos ver ejemplos de acceso a diferentes fuentes a través de un stream, pero lo aplicaremos sobre todo el acceso a ficheros, claro.
Flujos de entrada y salida
La primera diferenciación que haremos en los flujos de datos es si son de entrada o de salida.
- Flujos de entrada son aquellos que servirán para introducir datos desde el exterior al programa, es decir en la zona de memoria controlada por el programa (variables, …)
- Flujos de salida son aquellos que servirán para guardar los datos desde las variables del programa hasta el exterior, por ejemplo un archivo, para que se guardan de forma permanente.
Flujos y tipos de datos
Por medio del stream conseguiremos que un dato se guarde en un fichero (ya hemos visto que puede servir para llevarla a otros lugares, pero nosotros nos centraremos sobre todo en ficheros), o mejor dicho una serie de datos. Cuando guardamos muchos datos, se compactarán unas junto a las otras (lo que habíamos comentado como secuenciación de bits). Si intentamos recuperarlas, tendremos que tener mucho cuidado con el tamaño de cada una de los datos y su tipo. Vamos a poner un ejemplo:
-
Supongamos que queremos guardar un dato numérico en un entero (int). Los enteros, en Java, se guardan en 32 bits. Si queremos guardar el número 1.213.156.417, nos quedará en binario (los hemos puesto en grupos de 8 bits, para facilitar la lectura):
1
01001000 01001111 01001100 01000001
-
Supongamos ahora que queremos guardar dos números enteros, pero del tipo short, que sólo ocupa 16 bits. El número 18.511 se representa en binario como 01001000 01001111, y el número 19.521 se representa 01001100 01000001. Si ponemos un dato detrás de la otra (como se guardará en un archivo), el resultado será:
1
01001000 01001111 01001100 01000001
-
Supongamos ahora que queremos guardar la palabra HOLA. Si guardamos el código ASCII de cada letra tendremos: H (01001000), O (01001111), L (01001100) y A (01000001)
1
01001000 01001111 01001100 01000001
En resumen, las 3 informaciones (el número de 32 bits, los 2 números de 16 bits, y la palabra HOLA) se guardan de forma idéntica, como secuencia de bits.
Por lo tanto, la única manera de poder recuperar la información es saber de qué tipo es y el tamaño, además del orden como está guardada, claro. Los flujos de datos de Java transfieren los datos de forma transparente al programador. No hay que indicar la cantidad de bits que hay que transferir, sino que se deduce a partir del tipo de dato que la variable representa. Pero siempre tendremos que tener presente el tipo de datos y el orden.
Hay, sin embargo, una excepción con el tipo char. La multitud de estándares de codificación de caracteres existentes en la actualidad y la diversidad de formatos utilizados a la hora de implementar las codificaciones, usando según el caso 8, 16, 32 bits o incluso una longitud variable en función del carácter a representar, hacen que sea muy difícil tratar este tipo de datos como una simple secuencia de bytes.
Internamente, Java representa el tipo carácter con una codificación UNICODE de 16 bits (UTF-16) para soportar múltiples alfabetos aparte de la occidental. Aún así, es capaz de gestionar fuentes de datos (archivos entre otros) de varias codificaciones (ASCII, ISO-8859, UTF-8, UTF-16 …). En función de la codificación elegida, el número de bits utilizados en el almacenamiento variará. Se hace necesario, pues, un tratamiento especial a la hora de manipular estos datos. Como veremos, Java dispone de una jerarquía específica de clases orientadas a flujos de caracteres para hacer estos cambios y transformaciones totalmente transparentes al programador.
2 Manipulación de los flujos de datos
En Java no tendremos una única clase para manipular los flujos de datos y así alcanzar el contenido de los archivos. Es algo que a veces se le critica a Java, que hay una jerarquía muy extensa de flujos, y son muchas clases a recordar y utilizar. Por el contrario hace que sea muy versátil.
Estas clases se encontrarán en dos jerarquías, la de los flujos orientados a bytes y la de los flujos orientados a caracteres. Si nuestros datos son numéricos o de cualquier otro tipo que podamos imaginar (imágenes por ejemplo), nos convendrán las primeras. Si la información es de caracteres, deberemos utilizar la segunda jerarquía. La razón de que exista esta segunda jerarquía orientada a caracteres es la multitud de sistemas de codificación existentes. Como habíamos comentado en la pregunta anterior, Java utiliza internamente codificación UNICODE de 16 bits (UTF-16), donde cada carácter ocupa 16 bits y así poder soportar todos los lenguajes como el griego, árabe, cirílico, chino, … . Pero UTF-8 está muy extendido, y en esta codificación a veces un carácter ocupa 8 bits, y a veces 16. y no podemos olvidar otros sistemas de codificación, como ASCII, ISO-8859, … La jerarquía de clases orientadas a carácter soportará todas las codificaciones.
2.1 Flujos orientados a bytes
La raíz, la base de toda la jerarquía son InputStream y OutputStream, respectivamente para flujos de entrada y de salida. Comentaremos los flujos de entrada, y los de salida son totalmente paralelos.
La super-clase InputStream servirá para hacer la entrada desde cualquier dispositivo: fichero, array de bytes, una tuberia (para llevar datos desde otra aplicación), … Todas las clases de entrada heredarán de ella y servirán para especificar exactamente de dónde (por ejemplo un archivo: FileInputStream) o para dar alguna otra funcionalidad, como iremos viendo poco a poco. De este modo, los métodos que se definan tendrán que ser implementados en las clases que heredan de la super-clase asegurando uniformidad, cualquiera que sea la fuente.
Hagamos un vistazo rápido a la jerarquía de clases en la siguiente imagen:
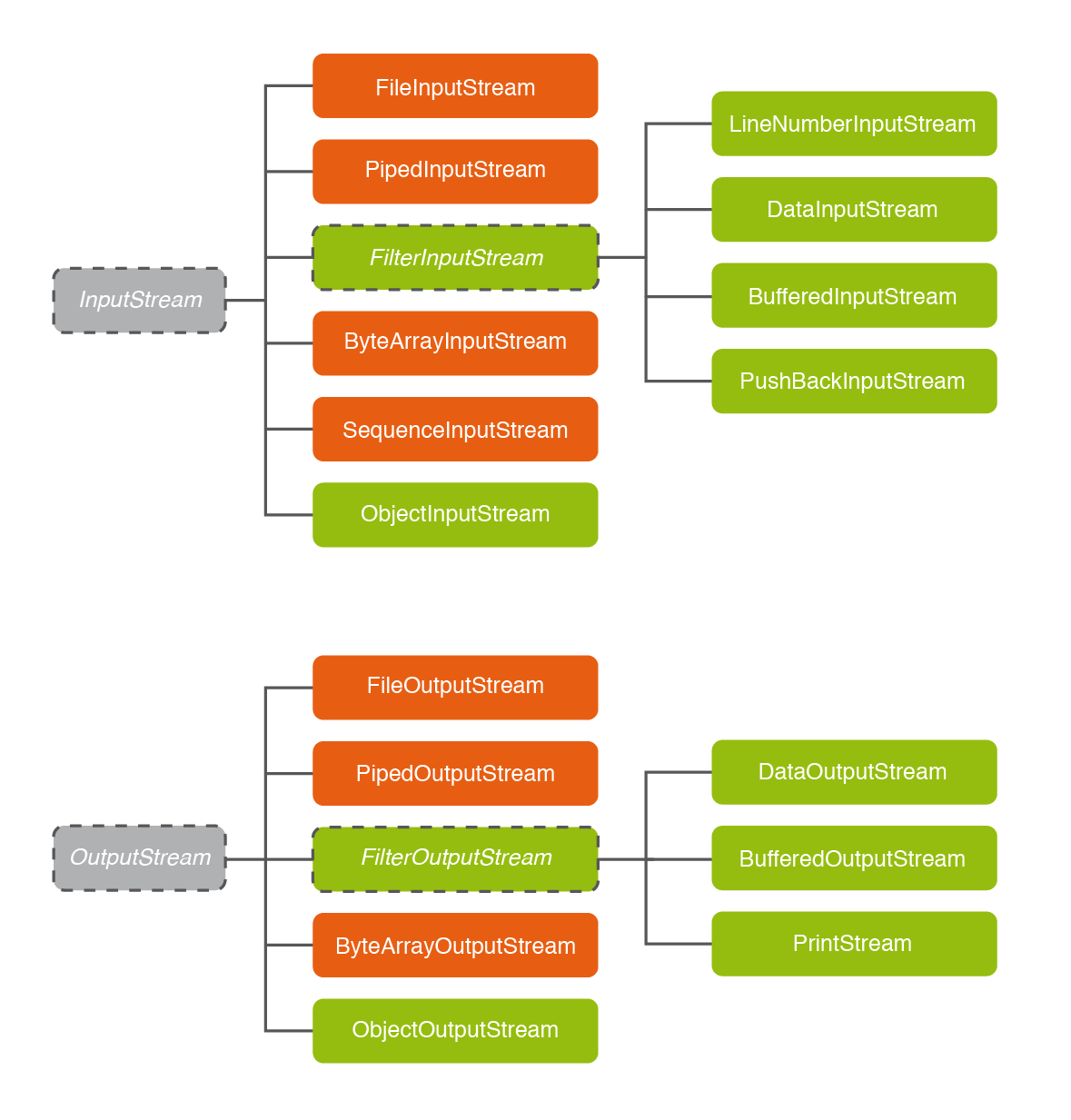 De momento miramos únicamente las que están en color naranja, que especificarán cuál será la fuente de datos:
De momento miramos únicamente las que están en color naranja, que especificarán cuál será la fuente de datos:
| Clase | Explicación |
|---|---|
FileInputStream |
Para leer desde un fichero |
PipedInputStream |
Para leer desde una tubería (es decir, información que viene de otro programa) |
ByteArrayInputStream |
La entrada será un array de bytes |
SequenceInputStream |
Servirá para enlazar dos entradas en una sola, secuencialmente |
Evidentemente nos centraremos en la primera, que es la que más nos interesa para la persistencia de los datos, pero pondremos algún ejemplo de las otras (concretamente ByteArrayInputStream).
Los flujos de salida son muy muy parecidos, todos ellos heredarán de OutputStream:
| Clase | Explicación |
|---|---|
FileOutputStream |
Para guardar información en un fichero |
PipedOutputStream |
Para sacar la información hacia una tubería (es decir, información que irá a otro programa)`` |
ByteArrayOutputStream |
La salida será un array de bytes |
Constructores de FileInputStream
Como hemos comentado, el que más nos interesa de todos los InputStream es el FileInputStream, para poder acceder a la información de un archivo. Dos son los constructores de FileInputStream:
FileInputStream(File f): en el parámetro se le pasa unFile(de los vistos en el tema anterior), que debe ser una referencia al archivo.FileInputStream(String nombre): en el parámetro se le pasa unStringcon el nombre (y la posible ruta) del archivo. Nos permitirá hacer referencia al archivo de forma más rápida, sin tener que pasar por un File.
Constructores de FileOutputStream
Cambiarán ligeramente respecto a los de entrada, ya que además de hacer referencia al archivo, opcionalmente podremos especificar la manera de escribir en el fichero en caso de que éste ya exista: bien añadiendo al final, o bien destruyendo la información anterior. Estos son los constructores:
FileOutputStream(File f): en el parámetro se le pasa unFile. Si no existía, lo creará; si ya existía borrará el contenido. En ambos casos lo abrirá en modo escritura.FileOutputStream(String nombre): igual que en el anterior, pero en el parámetro se le pasa unStringcon el nombre (y la posible ruta) del archivo.FileOutputStream(File f, boolean añadir): es como el primero, pero si en el segundo parámetro se le pasa true, en caso de que ya existiera el archivo, la información se añadirá al final, en lugar de sustituir la que ya había . Si en este parámetro se le pasa false borrará el contenido anterior (como en el primer caso).FileOutputStream(String nombre, boolean añadir): igual que en el anterior, pero en el primer parámetro se le pasa unStringcon el nombre (y la posible ruta) del archivo.
2.1.1 Métodos de InputStream
El primer método que debemos ver de InputStream es aquel que nos permite una lectura sencilla:
int read(): lee el siguiente byte del flujo de entrada y lo devuelve como un entero. Si no hay ningún byte disponible porque se ha llegado al final de la secuencia de bytes, se devolverá -1. Si no se puede leer el siguiente byte por alguna causa (por ejemplo si después de llegar al final intentamos leer otro byte, o porque se produce un error al leer la entrada) se lanzará una excepción del tipoIOException. Se trata de un método abstracto, que las clases especificas sobrescribirán adaptándolo a una fuente de datos concreta (un archivo, un array de bytes, …). Y observa como se trata de una lectura secuencial. Empezamos por el primer byte del archivo, y cadareadlee el siguiente byte hasta llegar al final. Los tratamientos que veremos en este tema serán siempre secuenciales.
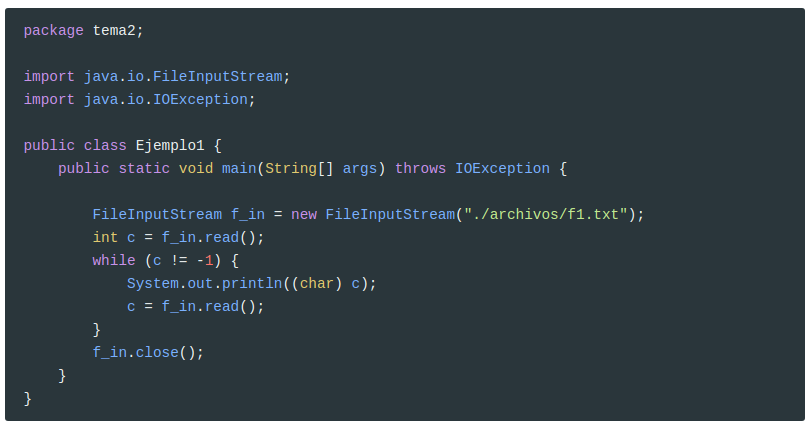
Antes de ver otros métodos, miramos un ejemplo. Para este ejemplo hace falta un fichero llamado f1.txt, que puede ser un archivo de texto creado con cualquier editor sencillito, como por ejemplo gedit o el Bloc de notas. Debe estar en el directorio del proyecto, y así no habrá que poner la ruta. Por ejemplo podríamos poner el siguiente contenido:
1
Hola, ¿qué tal?
Lo que hará el programa es sacar por pantalla carácter a carácter (en líneas diferentes).
Y esta es la salida en Ubuntu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
H
o
l
a
,
Â
¿
q
u
Ã
©
t
a
l
?
Quizás en Windows si que aparezcan bien todos los caracteres, ya que utiliza por defecto otra codificación. Pero no le daremos ahora importancia a que no aparezcan bien los caracteres especiales. Observa cómo estamos utilizando un InputStream, concretamente un FileInputStream, para leer un archivo de texto. Esto no es lo más apropiado, como ya habíamos comentado antes, sino que deberíamos utilizar algún flujo orientado a caracteres, y no orientado a bytes. El programa funcionará si utilizamos codificación ASCII (o ISO-8859) ya que cada carácter se guarda en un byte. Si nos despistamos y el fichero lo guardamos en UTF-8, no saldrán bien los caracteres como ç, ñ o vocales acentuadas (que se guardan en 2 bytes). Y si lo guardamos en UTF-16, aunque saldrá peor.
Si el archivo lo guardamos con Gedit (o Pluma) con codificación

El resultado es el siguiente:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
H
o
l
a
,
¿
q
u
é
t
a
l
?
Hemos utilizado el constructor que acepta un String como parámetro. Queda más corto, pero sería totalmente equivalente sustituir la construcción anterior por estas dos líneas
1
2
3
4
File f = new File("./archivos/f1.txt");
FileInputStream f_in = new FileInputStream(f);
Observa también como obligatoriamente tenemos que controlar la excepción IOException, en este caso a través de throws (para no gestionarla). El read obtiene un entero, que después intentamos convertir en carácter. Terminamos cuando el entero es -1.
Este segundo ejemplo tiene la entrada no desde un archivo, sino desde un ByteArrayInputStream. Aparte de que lo tenemos que inicializar diferente, podemos observar como el tratamiento posterior es idéntico:
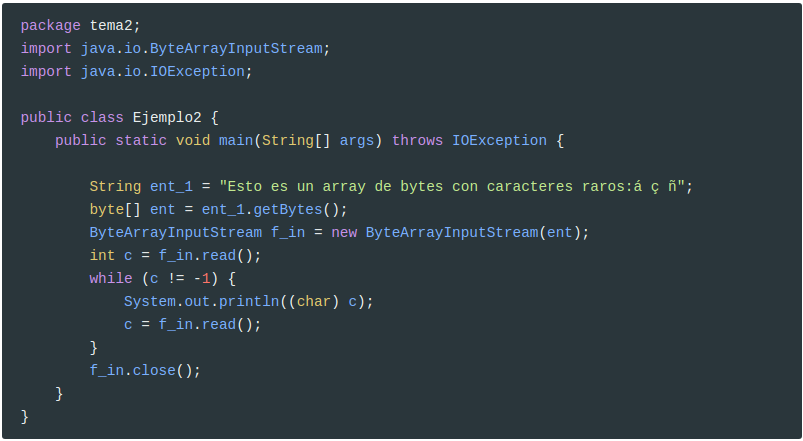
Otra vez los caracteres especiales saldrán mal, ya que en lugar de un InputStream (en este caso ByteArrayInputStream) lo más adecuado sería un flujo orientado a caracteres, pero como ejemplo sí que nos vale.
Miremos un tercer ejemplo, para ver el SequenceInputStream, donde se pueden pegar de forma secuencial diferentes InputStream. Tras este ejemplo ya nos centraremos en los ficheros, que es lo que nos interesa.
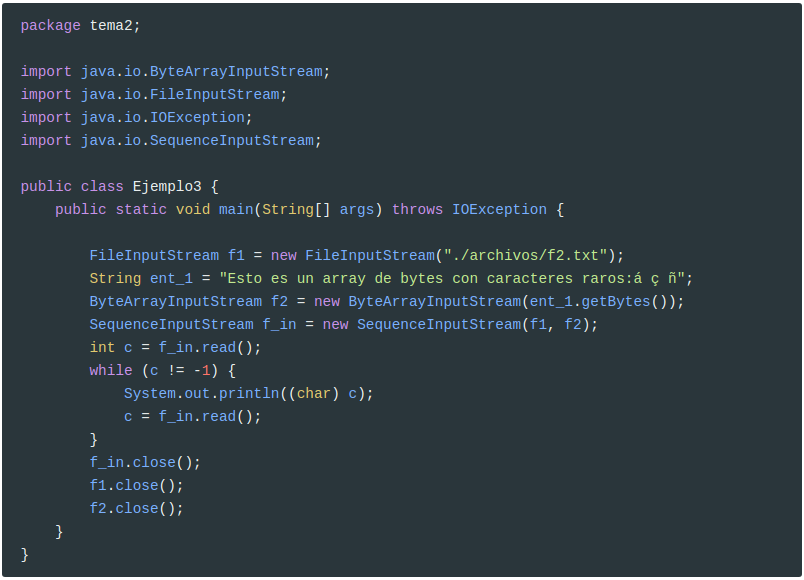
Otros métodos del InputStream son:
int read(byte[] buffer): lee un número determinado de bytes de la entrada, guardándolos en el parámetro (que actuará como un buffer). El número de bytes leídos será como máximo el tamaño del buffer, aunque podría ser menor (si no hay suficiente bytes, por ejemplo). El método devolverá el número de bytes que realmente se han leído como un entero. Si no hubiera ningún byte disponible, se devolverá -1.int available(): indica cuántos bytes hay disponibles para la lectura. Sobre todo serviría como condición de final de bucle (si hay 0 bytes disponibles, es que ya hemos acabado), aunque hay otras maneras de hacer la condición de final de bucle.long skip(long despl): salta, despreciando los mismos, tanto bytes como indica el parámetro. Podría ser que no pudiera saltar el número de bytes especificado por diferentes razones. Devuelve el número de bytes realmente saltados.int close(): cierra el flujo de datos. Siempre hay que cerrar todos los flujos abiertos.
Miremos otro ejemplo, utilizando ahora el buffer como argumento de read:
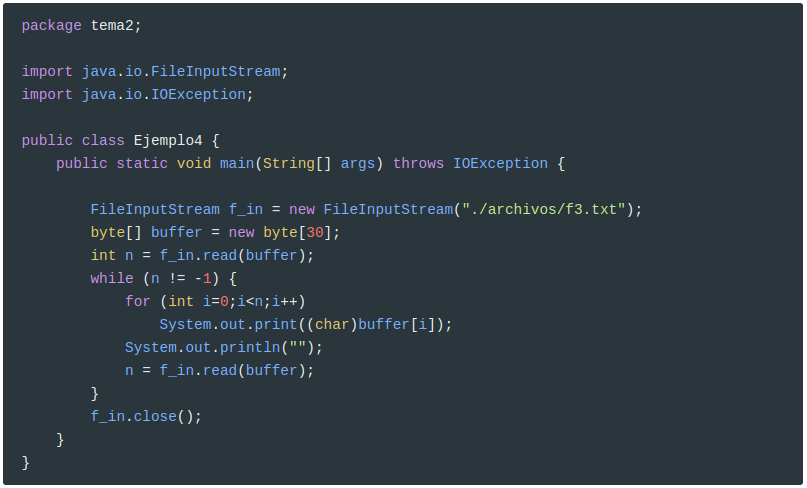
Se leerán los caracteres de 30 en 30, ya que el buffer es de este tamaño. Como se guarda en un buffer de bytes (bytes, no caracteres), tendremos que recorrer este buffer (hasta el número de caracteres leídos, que es n) convirtiendo cada byte en carácter. Hemos supuesto que en el fichero f3.txt tenemos un texto bastante largo como para ver el funcionamiento. Si por ejemplo el contenido de f3.txt es éste:
1
2
Hola. Esto es un texto más largo, para ver cómo se gestionan los bytes con un buffer de 30 caracteres.
Como que lo leemos como texto, los caracteres especiales puede que no salgan bien.
Esta sería la salida:
1
2
3
4
5
6
7
8
Hola. Esto es un texto m£s lar
go, para ver cmo se gestionan
los bytes con un buffer de 30
caracteres.
Como que lo leemo
s como texto, los caracteres e
speciales puede que no salgan
bien.
Recuerda que estamos leyendo un archivo de texto desde un InputStream, cosa nada conveniente ya que los caracteres como ç, ñ, o vocales acentuadas difícilmente podremos hacer que aparezcan bien. Lo arreglaremos con los flujos orientados a carácter.
2.1.2 Métodos de OutputStream
Empezamos también por el más sencillo y primordial, el método que escribe un byte (recuerda que estamos en flujos orientados a bytes).
void write(int byte): escribe el byte pasado como parámetro en el flujo de salida. Aunque el parámetro es de tipo int, sólo se escribirá un byte. Si no se pudiera hacer la escritura por cualquier motivo (por ejemplo, disco lleno), se lanzará una excepción de tipoIOException.
Al igual que en el apartado anterior, vamos a ver un ejemplo sencillo de utilización, en el que guardaremos en un fichero el contenido de una cadena (aunque ya sabemos que no es el más apropiado utilizar flujos orientados a bytes para información caracteres).
En este primer ejemplo del OutputStream trabajaremos sobre un archivo inexistente. Se podrá comprobar que el resultado será la creación del fichero con el contenido. Debemos hacer constar que si no se cierra el fichero (mejor dicho el flujo de salida) podría ser que no se guardara nada en el fichero. Por lo tanto es una operación bien importante que no debemos olvidar.

En el constructor del OutputStream no hemos indicado el segundo parámetro, aquel que indicaba si era para añadir o no, y por lo tanto si no existía el fichero lo creará, pero si ya existía el fichero, destruirá su contenido y lo sustituirá por el nuevo contenido. Por eso si volvemos a ejecutar el programa, tendremos el mismo resultado.
1
Contenido para el fichero.
La codificación del archivo será la que tenga por defecto el Sistema Operativo, que en el caso de Ubuntu es UTF-8, y en el caso de Windows es ISO-8859. Vamos a probar a sustituir el constructor, poniendo ahora
1
FileOutputStream f_out = new FileOutputStream("./archivos/f4.txt", true);
Si lo ejecutamos otra vez, veremos que añadirá al final, sin destruir lo que ya había.
1
Contenido para el fichero.Contenido para el fichero.
Otros métodos del OutputStream son:
void write(byte[] buffer): escribe el contenido del array de bytes en el fichero. Se necesita que el buffer no sea nulo, o provocaremos un error.void write(byte[] buffer, int pos, int largo): escribe en el archivo el contenido del array que está a partir de la posición pos y tantos bytes como señale largo.void flush(): Guardar los datos en un fichero es una operación relativamente lenta, ya que es acceder a un dispositivo lento (mejor dicho, no tan rápido como la memoria). Es habitual que se utilice una memoria intermedia para que las cosas no vayan tan lentas (como si fuera una caché). Pero puede que los datos no estén guardadas todavía en el archivo, sino que aún estén en esta caché. El método flush obliga a escribir los bytes que quedan todavía en la caché físicamente el archivo de salida.void close(): cierra el flujo de salida, liberando los recursos. Si quedaba algo en la caché, se guardará en el archivo y se cerrará el flujo.
En este ejemplo se copia el contenido del archivo f3.txt en el fichero f5.txt, pero en lugar de ir byte a byte, iremos de 30 en 30, con un buffer de 30 posiciones.
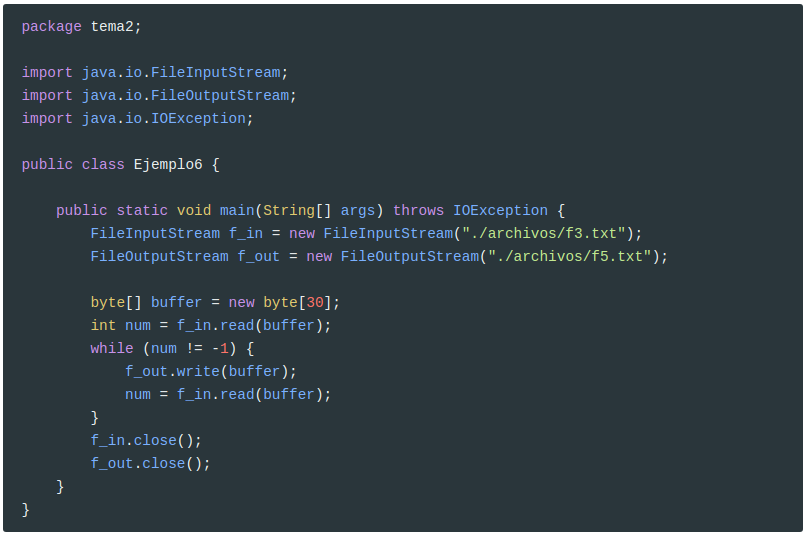
De este modo, la última vez que se lee es muy posible que no haya exactamente 30 caracteres. Si hay menos de 30 caracteres, sólo se leerán los que quedan al principio del buffer, y en el resto del buffer estará la información anterior, la de la penúltima lectura. En definitiva, tenemos “basura”, y si no lo controlamos el resultado no será el correcto. Este seá el contenido de f5.txt:
1
2
3
Hola. Esto es un texto más largo, para ver cómo se gestionan los bytes con un buffer de 30 caracteres.
Como que lo leemos como texto, los caracteres especiales puede que no salgan bien.
les puede que no salgan
Ha salido de esta manera porque la última vez sólo se han leído 6 bytes. Los 24 restantes tienen la información todavía de la penúltima lectura. Para hacerlo de forma correcta, nos aprovechamos de que read(buffer) devuelve el número de bytes realmente leídos, para escribir exactamente este número. Por tanto sustituiremos la línea:
1
f_out.write(buffer);
por
1
f_out.write(buffer,0,num);
Ahora el contenido de f5.txt será idéntico a f3.txt
Importante. Para asegurarnos de que realmente escribimos en el archivo y no se queda nada en la memoria intermedia, tenemos que cerrar siempre los flujos de salida. Si nos olvidamos de cerrarlos, es muy fácil que no se acabe de escribir físicamente en el fichero.
2.2 Flujos orientados a caracteres
Trabajar con caracteres implica una dificultad apreciable, debido sobre todo a la diversidad de codificaciones existentes.
Para poder solucionarlo, Java dispone de dos jerarquías, una de entrada y una de salida, distintas de las que ya hemos visto para bytes (que eran InputStream y OutputStream). Estas jerarquías para caracteres serán muy similares a las de bytes, pero siempre orientadas a caracteres.
Al igual que en los casos anteriores, tendremos unas clases abstractas, Reader y Writer, que no se pueden instanciar directamente (no podremos crear un objeto de estas clases). Servirán para homogeneizar todos los flujos de entrada y de salida orientados a carácter.
La super-clase Reader servirá para hacer la entrada desde cualquier dispositivo: fichero, array de caracteres, una tuberia (para llevar datos desde otra aplicación). Todas las clases de entrada heredarán de ella, y servirán para especificar exactamente de dónde (por ejemplo un archivo: FileReader) o para dar alguna otra funcionalidad, como iremos viendo poco a poco. De este modo, los métodos que se definen se tendrán que implementar en las clases que heredan de ella y se asegura una uniformidad, cualquiera que sea la fuente.
Hagamos un vistazo rápido a la jerarquía de clases en la siguiente imagen:
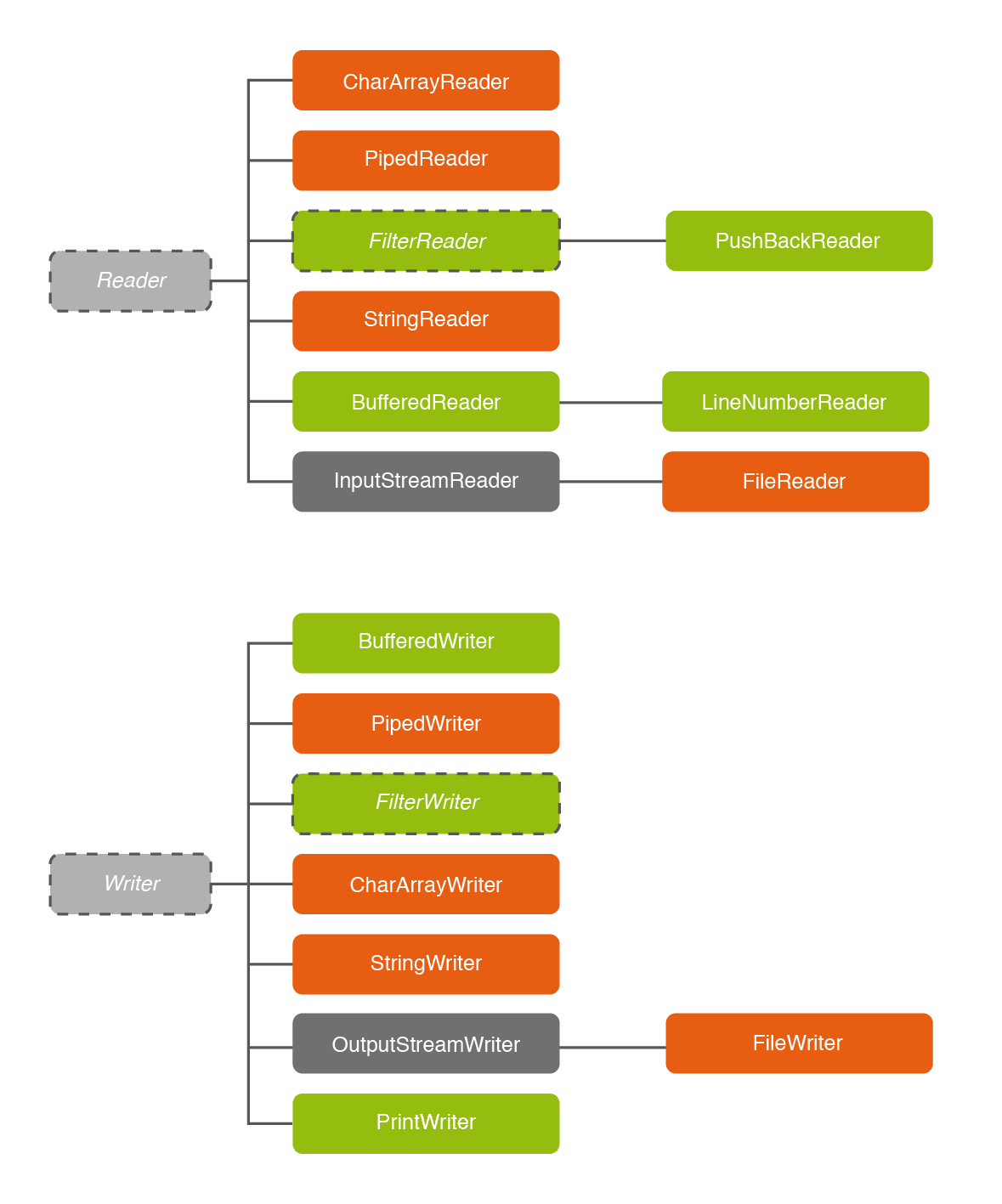
De momento miramos únicamente las que están en color naranja, que especificarán cuál será la fuente de datos:
| Clase | Explicación |
|---|---|
FileReader |
Para leer caracteres de un fichero |
PipedReader |
Para leer desde una tubería |
CharArrayReader |
La entrada será un Array de caracteres |
StringReader |
La entrada será un String |
Evidentemente nos centraremos en la primera, que es la que más nos interesa para la permanencia de los datos.
Los flujos de salida son muy muy parecidos, todos ellos heredarán de Writer:
| Clase | Explicación |
|---|---|
FileWriter |
Para guardar caracteres en un fichero |
PipedWriter |
Para sacar caracteres hacia una tubería |
CharArrayWriter |
La salida será un Array de caracteres |
StringWriter |
La salida será un String |
Debemos hacer constar que las clases de almacenamiento interno, como CharArrayReader, CharArrayWriter, StringReader, StringWriter, PipedReader, PipedWriter utilizan siempre la codificación propia de Java (unicode de 16 bits: UTF-16), ya que guardan los datos en la memoria basándose en los tipos datos de tratamiento de caracteres de Java (char y String).
En cambio las clases FileReader o FileWriter cogen la codificación por defecto del sistema operativo anfitrión. El usuario no puede seleccionar diferentes sistemas de codificación al crear las instancias. Así, una máquina virtual Java sobre Windows utilizará, por defecto, la codificación ISO-8859-1, pero si corre sobre Linux, la codificación será UTF-8. De todas formas veremos que sí podremos llegar a especificar cuál es el juego de caracteres que queremos utilizar en la apartado 3.3. Intentaremos ver ejemplos de todo.
Constructores de FileReader
De forma totalmente paralela a los flujos orientados a byte, el FileReader tiene dos constructores, aceptando como parámetro un File o un String (con el nombre del archivo). La diferencia ahora es que la unidad de transferencia será el carácter (en lugar de un byte):
FileReader(File f): en el parámetro se le pasa unFile(de los vistos en el tema anterior), que debe ser una referencia al archivo.FileReader(String nombre_f): en el parámetro se le pasa un String con el nombre (y la posible ruta) del archivo. Nos permitirá hacer referencia al archivo de forma más rápida, sin tener que pasar por unFile.
Constructores de FileWriter
También totalmente paralelo al FileOutputStream. Cambiarán ligeramente respecto a los de entrada, ya que además de hacer referencia al archivo, opcionalmente podremos especificar la manera de escribir en el fichero en caso de que éste ya exista: bien añadiendo al final, o bien destruyendo la información anterior. Estos son los constructores:
FileWriter(File f): en el parámetro se le pasa unFile. Si no existía, lo creará; si ya existía borrará el contenido. En ambos casos lo abrirá en modo escritura.FileWriter(String nombre_f): igual que en el anterior, pero en el parámetro se le pasa un String con el nombre (y la posible ruta) del archivo.FileWriter(File f, boolean añadir): es como el primero, pero si en el segundo parámetro se le pasa true en lugar de sustituir lo que ya había, la información se añadirá al final. Si en este parámetro se le pasa false borrará el contenido anterior (como en el primer caso).FileWriter(String nombre_f, boolean añadir): igual que en el anterior, pero en el primer parámetro se le pasa un String con el nombre (y la posible ruta) del archivo.
2.2.1 Métodos del Reader
Los métodos del Reader son absolutamente similares a los del InputStream. La diferencia es que ahora leerá siempre un carácter. Y no tendremos que preocuparnos por el formato en que está guardado, y de si ocupa uno o dos bytes. Siempre lo leerá bien, cualquiera que sea la codificación utilizada, como ya habíamos comentado antes:
int read(): lee el siguiente carácter del flujo de entrada y lo devuelve como un entero. Si no hay ningún carácter disponible por haber alcanzado el final de la secuencia, se devolverá -1. Si no se puede leer el siguiente carácter por alguna causa (por ejemplo si después de llegar al final intentamos leer otro carácter, o porque se produce un error al leer la entrada) se lanzará una excepción del tipoIOException. Se trata de un método abstracto, que las clases especificas sobrescribirán adaptándolo a una fuente de datos concreta (un archivo, un array de caracteres, …).
Antes de ver otros métodos, miramos un ejemplo que es idéntico al primer ejemplo del InputStream, pero cambiando FileInputStream para FileReader. Leerá el mismo archivo llamado f1.txt, utilizado en ese momento, pero ahora seguramente leerá todos los caracteres bien. Lo que hará es sacar por pantalla carácter a carácter (en líneas diferentes).
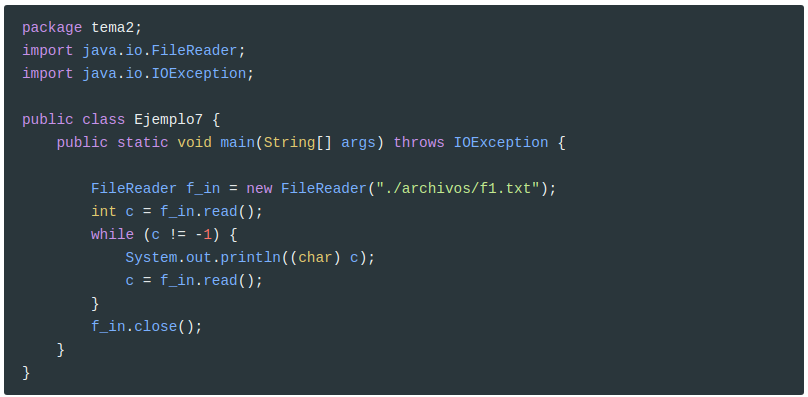
Ahora seguramente sí habrá leído bien todos los caracteres, incluyendo ñ, ç, vocales acentuadas, etc. Si aún tenemos el mismo contenido en f1.txt, el resultado será ahora:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
H
o
l
a
,
¿
q
u
é
t
a
l
?
Lo más normal es que al crear el fichero f1.txt con algún editor, lo guardamos con la codificación por defecto, que en caso de Windows es ASCII (o ISO-8859) y en el caso de Linux es UTF-8. Y luego desde Java, el FileReader utilizará la codificación por defecto del sistema operativo. Es decir que en Linux el archivo debe estar guardado en UTF-8 para que lo pueda leer bien, y en Windows en ASCII.
Miremos también el ejemplo equivalente al segundo. Allí utilizábamos un ByteArrayInputStream como entrada. Ahora podríamos utilizar un CharArrayReader, pero lo haremos con un StringReader, quedando más corto. Aparte de que lo tenemos que inicializar de forma diferente, podemos observar como el tratamiento posterior es idéntico:
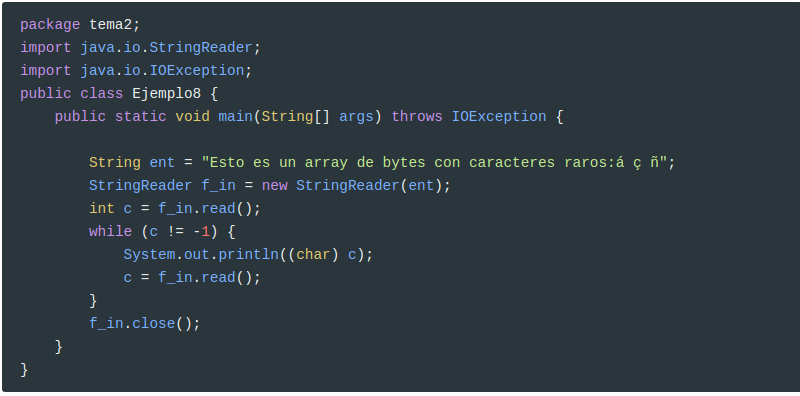
Otros métodos del Reader son:
int read(char[] buffer): lee un número determinado de caracteres de la entrada, guardándolos en el parámetro (que actuará como un buffer). El número de caracteres leídos será como máximo el tamaño del buffer, aunque podría ser menor (si no hay suficiente caracteres, por ejemplo). El método devolverá el número de caracteres que realmente se han leído como un entero. Si no hubiera ningún carácter disponible, se devolvería -1.int available(): indica cuántos caracteres hay disponibles para la lectura. Sobre todo serviría como condición de final de bucle: si hay 0 caracteres disponibles, es que ya hemos terminado. Sin embargo, hay otras maneras de hacer la condición de final de bucle.long skip(long despl): salta, despreciando los mismos, tantos caracteres como indica el parámetro. Podría ser que no pudiera saltar el número de caracteres especificado por diferentes razones. Vuelve el número de caracteres realmente salteados.int close(): cierra el flujo de datos.
Miremos otro ejemplo, utilizando ahora el buffer como argumento de read. Es idéntico al del apartado del InputStream. La diferencia es que ahora se deberían leer bien todos los caracteres.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package tema2;
import java.io.FileReader;
import java.io.IOException;
public class Ejemplo9 {
public static void main(String[] args) throws IOException {
FileReader f_in = new FileReader("./archivos/f3.txt");
char[] buffer = new char[30];
int n = f_in.read(buffer);
while (n != -1) {
for (int i=0;i<n;i++)
System.out.print(buffer[i]);
System.out.println("");
n = f_in.read(buffer);
}
f_in.close();
}
}
Se leerán los caracteres de 30 en 30, ya que el buffer es de este tamaño. Como ahora se guarda en un buffer de caracteres, tendremos que recorrer este buffer (hasta el número de caracteres leídos, que es n). Hemos supuesto que en el fichero f3.txt tenemos un texto bastante largo como para ver el funcionamiento.
Esta sería la salida:
1
2
3
4
5
6
7
8
Hola. Esto es un texto más lar
go, para ver cómo se gestionan
los bytes con un buffer de 30
caracteres.
Como que lo leemo
s como texto, los caracteres e
speciales puede que no salgan
bien.
Efectivamente, se han leído todos los caracteres perfectamente.
2.2.1 Métodos del Writer
Empezamos también por más sencillo y primordial, el método que escribe un carácter.
void write(int car): escribe el carácter pasado como parámetro en el flujo de salida. En caso de que sea unFileWriter, escribirá el carácter con la codificación predeterminada del S.O. : En Windows ISO-8839 y en Linux UTF-8. Si no se pudiera hacer la escritura por cualquier motivo (por ejemplo, disco lleno), se lanzará una excepción de tipo IOException.
Al igual que en el apartado anterior, vamos a ver un ejemplo sencillo de utilización, en el que guardaremos en un fichero el contenido de una cadena, ahora ya sin miedo a los caracteres extraños.
En este primer ejemplo de Writer trabajaremos sobre un archivo inexistente. Se podrá comprobar que el resultado será la creación del fichero con el contenido. Debemos hacer constar que si no se cierra el fichero (mejor dicho el flujo de salida) podría ser que no se guardara nada en el fichero. Por lo tanto es una operación bien importante que no debemos olvidar.

En el constructor del Writer no hemos indicado el segundo parámetro, aquel que indicaba si era para añadir o no, y por lo tanto si no existía el fichero lo creará, pero si ya existía el fichero, destruirá su contenido y lo sustituirá por el nuevo contenido. Por eso si volvemos a ejecutar el programa, tendremos el mismo resultado en f6.txt
1
Contenido para el fichero, sin miedo a los caracteres raros:á ç ñ
Otros métodos de Writer son:
void write(char[] buffer): escribe el contenido del array de caracteres en el archivo. El buffer no debe ser nulo, o provocaremos un error.void write(char[] buffer, int pos, int largo): escribe en el archivo el contenido del array que está a partir de la posición pos y tantos caracteres como señale largo.void flush(): Guardar los datos en un fichero es una operación relativamente lenta, ya que es acceder a un dispositivo lento (mejor dicho, no tan rápido como la memoria). Es habitual que se utilice una memoria intermedia para que las cosas no vayan tan lentas (como si fuera una caché). Pero puede que los datos no estén guardadas todavía en el archivo, sino que aún estén en esta caché. El método flush obliga a escribir los caracteres que quedan todavía en la caché físicamente el archivo de salida.void close(): cierra el flujo de salida, liberando los recursos. Si quedaba algo en la caché, se guardará en el archivo y se cerrará el flujo.
Estos métodos son totalmente similares a los del OutputStream. Aparte de estos, el Writer tiene otro, que puede ser especialmente útil para caracteres:
void write(String texto): escribe todo el contenido del String en el fichero.
3 Flujos decoradores
Llamamos clases “decoradores” a aquellas que heredan de una clase determinada y sirven para dotar de una funcionalidad extra que no tenía la clase original. En los flujos, en los de entrada y en los de salida, veremos unos cuantos “decoradores” que nos permitirán una funcionalidad extra: leer o escribir una línea entera (en lugar de byte a byte, o carácter a carácter), o guardar con determinado formato de datos, … En el caso de caracteres también nos permitirán elegir la codificación (ISO-8859-1, UTF-8, UTF-16, …). Iremos viéndolas poco a poco, clasificados por la clase raíz, es decir, por una lado los decoradores de InputStream y OutputStream (orientados a byte), y por otra parte a los de Reader y Writer (orientados a carácter )
3.1 Decoradores de InputStream y OutputStream
Como hemos comentado nos servirán para dar una funcionalidad extra. Son los que están en verde en la siguiente imagen:
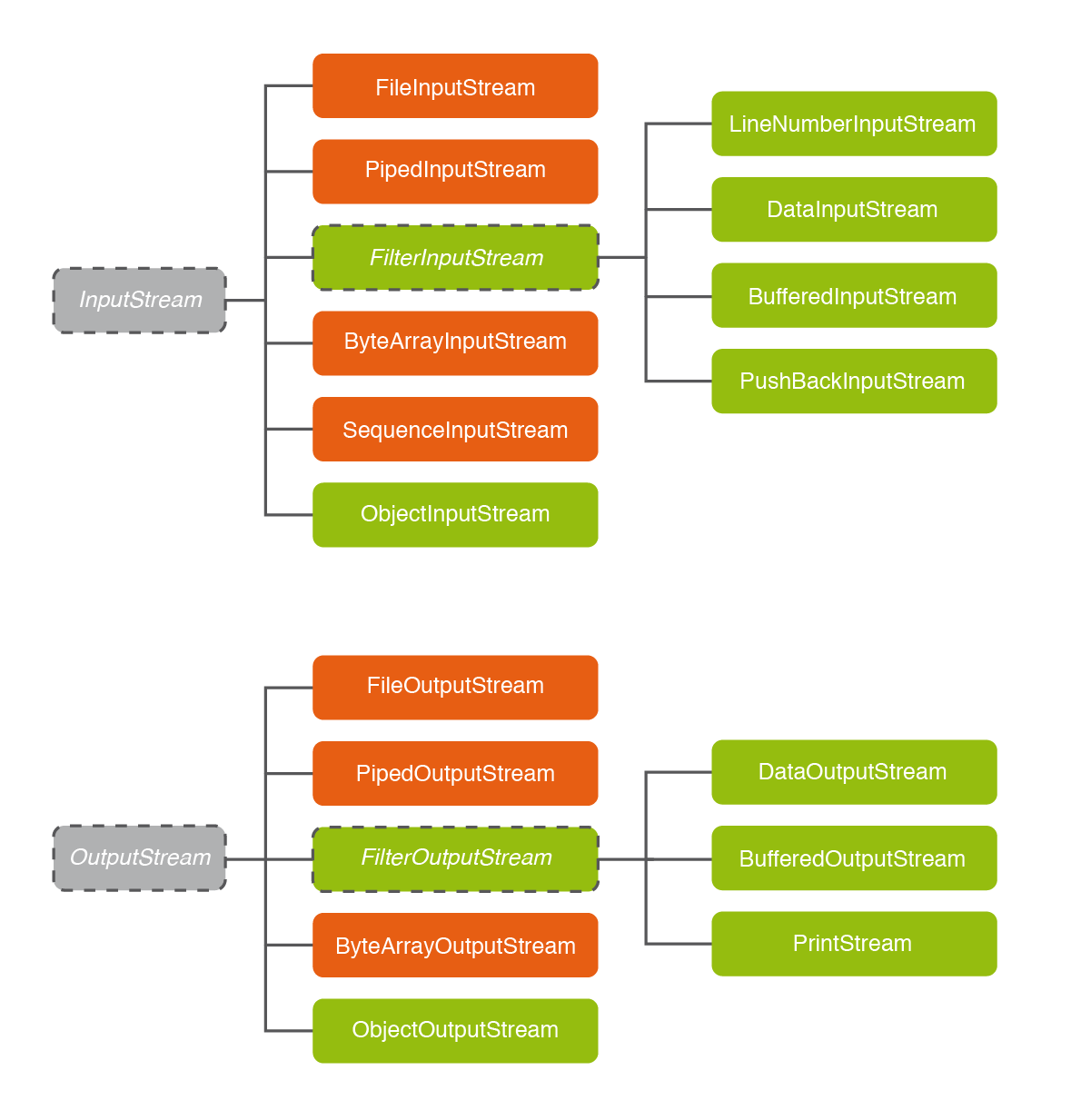
Fijémonos primeros en los decoradores de InputStream:
| Clase | Explicación |
|---|---|
FilterInputStream |
No es instanciable, únicamente está para que las demás dependan de ella (no la veremos) |
LineNumberInputStream |
Agregar el número de línea de cada línea del InputStream (no la veremos) |
DataInputStream |
Permite leer datos de cualquier tipo de datos: entero, real, booleano, … |
BufferedInputStream |
Monta un buffer de entrada (no la veremos) |
PushBackInputStream |
Permite retroceder un byte en la lectura, y por lo tanto permite ir hacia atrás (no la veremos) |
ObjectInputStream |
Permite leer todo un objeto |
Y de forma casi paralela tenemos los decoradores de OutputStream:
| Clase | Explicación |
|---|---|
FilterOutputStream |
No es instanciable, únicamente está para que las demás dependan de ella (no la veremos) |
DataOutputStream |
Permite guardar el flujo de datos de salida datos de cualquier tipo: entero, real, booleano, … |
BufferedOutputStream |
Monta un buffer de salida (no la veremos) |
PrintStream |
Permite escribir datos de diferentes tipos, y tiene también los métodos printf y println |
ObjectOutputStream |
Permite escribir (serializar) todo un objeto |
Los comentamos un poquito más:
BufferedInputStream y BufferedOutputStream nos ofrecen un buffer de entrada y de salida respectivamente, para hacer la transferencia más efectiva. En la práctica nos ofrecerá pocas funcionalidades útiles (aparte de la eficiencia en la transferencia, claro). Cuando veamos los decoradores de flujos orientados a caracteres, sí encontraremos utilidades a los decoradores similares a estos, como por ejemplo leer o escribir una línea entera de caracteres. Pero estos orientados a bytes, no los veremos.
DataInputStream y DataOutputStream nos ofrecerán la posibilidad de leer o escribir cómodamente datos de diferentes tipos: entero, real, booleano, strings, … Los veremos en detalle en el próximo tema.
ObjectInputStream y ObjectOutputStream (que curiosamente son los únicos que no dependen de FilterInputStream y FilterOutputStream) nos permitirán guardar o recuperar de golpe todo un objeto, es decir todas sus propiedades (los datos del objeto). No tendremos que preocuparnos ni del orden ni del tipo de las propiedades del objeto: cuando escribimos el objeto, se guardarán todos los datos de forma compacta; y cuando leemos se recuperarán de forma correcta. Es por tanto una pareja de clases de extrema utilidad para guardar objetos, que en definitiva son la esencia de la programación en Java. Los veremos en detalle en el próximo tema.
PrintStream
Lo único que nos queda es lo que veremos ahora con un poquito más de detalle: PrintStream. Nos permitirá básicamente 3 cosas:
-
Escribir datos de más de un tipo de datos. Por ejemplo
print(5.25)escribe un número real, yprint("Hola")escribe todo un string. -
Dar un determinado formato a la salida, con la funcionalidad de
printf -
Escribir toda una línea con
println, es decir, terminar un dato con el retorno de carro, para bajar de línea.
Miremos un ejemplo que nos puede dar idea de su funcionalidad.
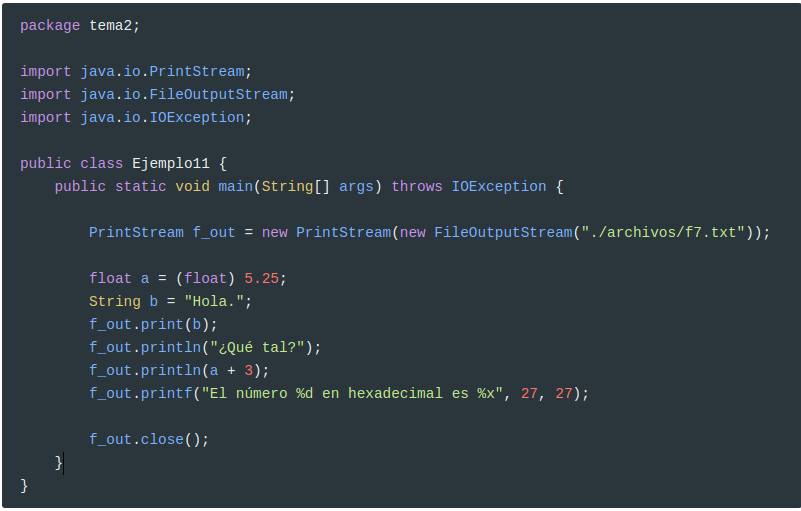
Nos creará el fichero f7.txt con el siguiente contenido:
1
2
3
Hola.¿Qué tal?
8.25
El número 27 en hexadecimal es 1b
En realidad PrintStream, aparte del constructor que acepta un OutputStream, también tiene otro que acepta un File e incluso otro que acepta un String con el nombre del archivo. Por lo tanto, la siguiente sentencia también nos funcionaría:
1
PrintStream f_out = new PrintStream("./archivos/f7.txt");
3.2 Decoradores de Reader y Writer
Veamos ahora los decoradores de la jerarquía Reader y Writer. Vuelven a ser los de color verde. Los de color gris InputStreamReader y OutputStreamWriter son conversores que permiten pasar un InputStream a un Reader y un OutputStream a Writer. Los veremos en la siguiente pregunta.
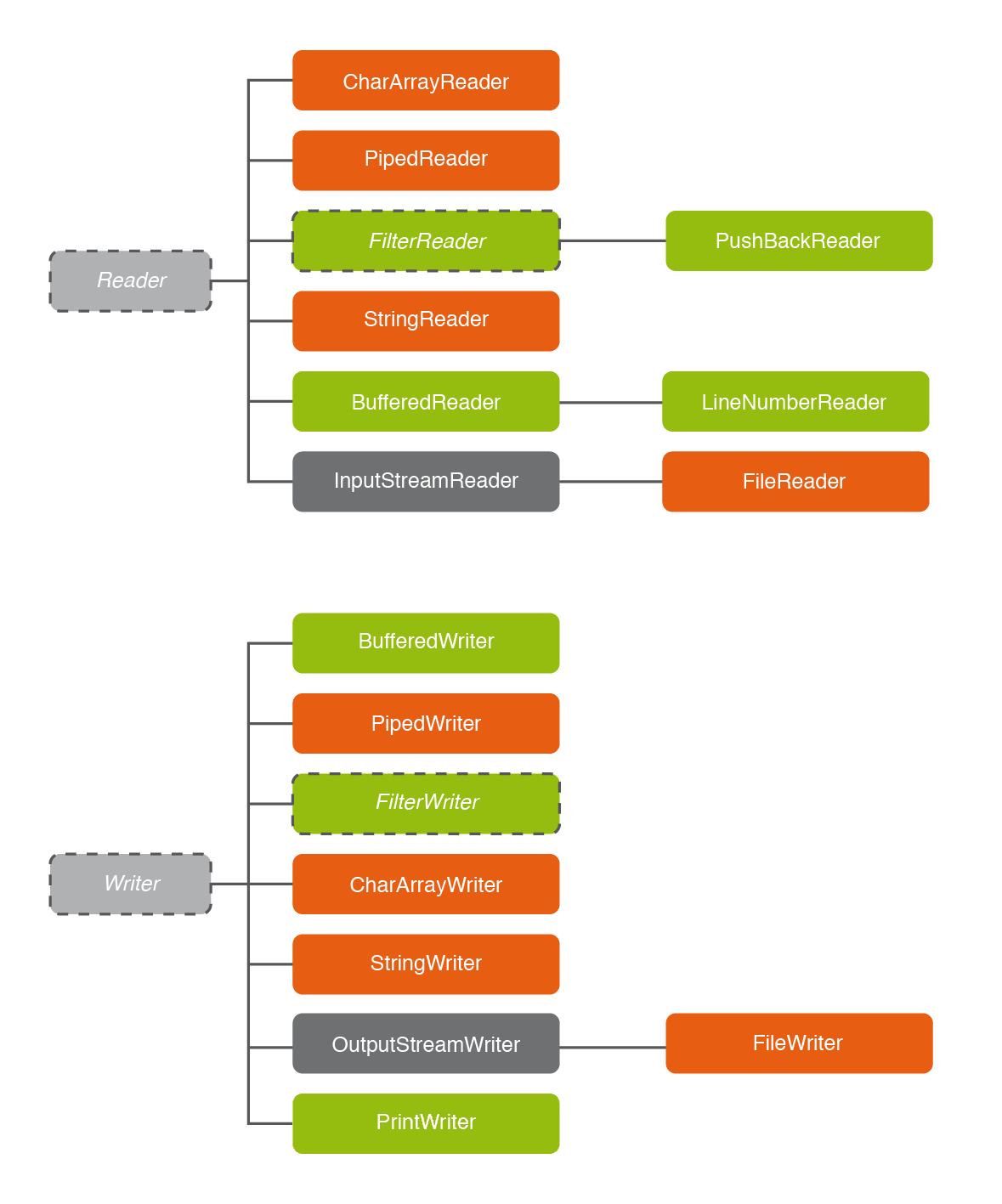
Fijémonos primeros en los decoradores de Reader:
| Clase | Explicación |
|---|---|
FilterReader |
No es instanciable, únicamente está para que las demás dependan de ella (no la veremos) |
PushBackInputStream |
Permite retroceder un carácter en la lectura, y por lo tanto permite ir hacia atrás (no la veremos) |
BufferedReader |
Monta un buffer de entrada, y permite entre otras cosas leer una línea entera |
LineNumberReader |
Agrega el número de línea de cada línea del archivo (no la veremos) |
Y de forma casi paralela tenemos los decoradores de Writer:
| Clase | Explicación |
|---|---|
FilterWriter |
No es instanciable, únicamente está para que las demás dependan de ella (no la veremos) |
BufferedWriter |
Monta un buffer de salida, y permite entre otras cosas escribir una línea entera |
PrintWriter |
Permite escribir datos de diferentes tipos, y tiene también los métodos printf y println |
PrintWriter funciona casi exactamente igual que el PrintStream, y para caracteres es más útil que el otro (por ser Writer), por lo tanto es el candidato a recordar. El BufferedReader sí nos ofrecerá facilidades interesantes, como leer una línea entera. En cambio el BufferedWriter no nos ofrece tantas facilidades como el PrintWriter, es un poco más incómodo.
BufferedReader y BufferedWriter. PrintWriter
BufferedReader y BufferedWriter montan un buffer (de entrada y de salida respectivamente) de caracteres para hacer más eficiente la transferencia. Aparte de esto tendrán unos métodos que nos serán muy útiles.
BufferedReader
readLine()nos permite leer una línea entera de archivo (hasta el final de línea). Esto es de mucha utilidad en los archivos de texto.
BufferedWriter
newline()que permite introducir el carácter de salto de líneawrite(String cad, int pos, int largo)que permite escribir todo un string, o una parte de ella, especificando donde comienza lo que queremos escribir y la longitud.
Como veis el BufferedReader sí que nos ofrece la posibilidad de leer una línea entera, pero en cambio el BufferedWriter se queda un poco corto. Por ello preferiremos el PrintWriter.
PrintWriter
-
print(cualquier_tipo), que permite imprimir un dato de cualquier tipo: booleano, char, todos los numéricos, string, … Será seguramente el que más utilizaremos. println(cualquier_tipo), aparte de todo lo que haceprint, bajan de líneaprintf()que permite dar un formato
Veamos un sencillo ejemplo para copiar el contenido de un archivo de texto y modificarlo ligeramente. Lo más cómodo será ir línea a línea. Por lo tanto utilizaremos el BufferedReader para leer líneas, y el PrintWriter para escribir líneas. La ligera modificación consistirá en poner el número de línea delante.
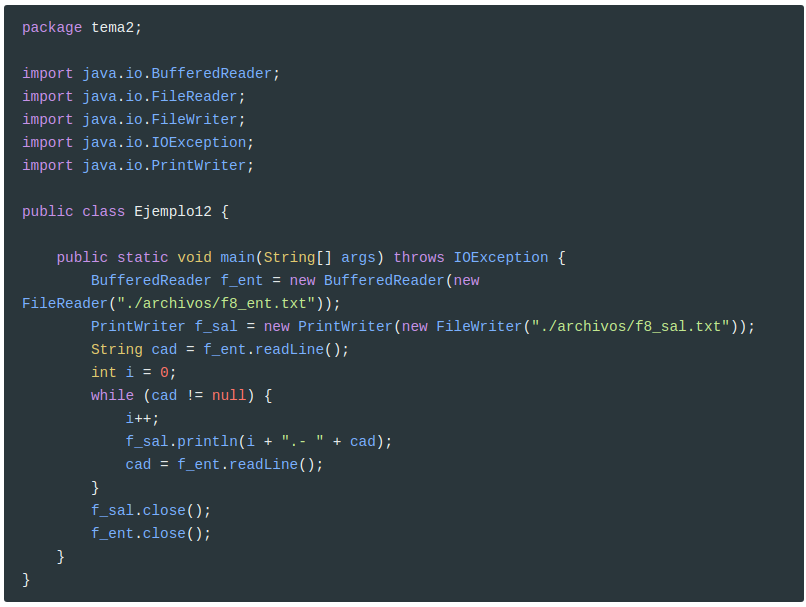
Si en el archivo de entrada (f8_ent.txt) tenemos guardada la siguiente información (introducida con el notepad o gedit):
1
2
3
Primera
Segunda
Tercera
En el fichero de salida tendremos (f8_sal.txt):
1
2
3
1.- Primera
2.- Segunda
3.- Tercera
3.3 Conversores: InputStreamReader i OutputStreamWriter
Una vez vistas las jerarquías de las clases InputStream-OutputStream por un lado, y Reader-Writer por otra, veremos ahora unas clases que servirán para pasar de una jeraquía a otra. Es decir, poder pasar un InputStream a Reader, o lo que es lo mismo, un flujo orientado a bytes en un flujo orientado a caracteres. Y lo mismo con el OutputStream y el Writer.
InputStreamReader: pasa unInputStreamaReader. Acepta como parámetro elInputStreamy da como resultado unReader.OutputStreamWriter: pasa unOutputStreamaWriter. Acepta como parámetro elOutputStreamy da como resultado unWriter.
Además en el constructor de los dos, InputStreamReader y OutputStreamWriter, tenemos la posibilidad de especificar el tipo de codificación, además del InputStream o OutputStream. Esto nos será muy útil, porque hasta el momento no podíamos elegir el tipo de codificación de un FileReader o FileWriter que era UTF-8 en el caso de Linux, y ASCII (mejor dicho su extensión ISO-8859-1) en el caso de Windows.
Miremos este ejemplo, en el que transformamos el mismo archivo de una configuración a otra. Aprovechamos alguno de los archivos que ya disponemos (por ejemplo f3.txt, que tenía caracteres especiales como vocales acentuadas). En el ejemplo lo tendremos en codificación UTF-8, ya que está probado en Linux. Lo transformaremos a ISO-8859-1.
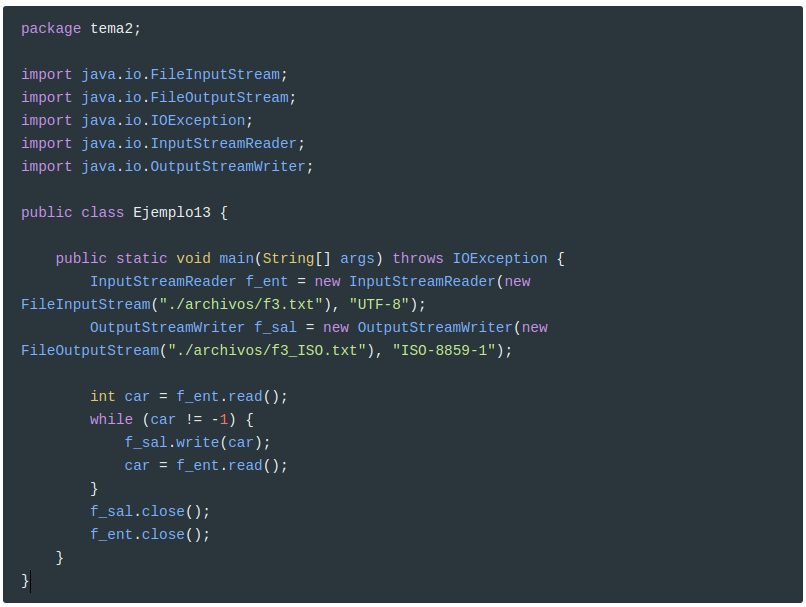
Hemos puesto la entrada explícitamente que sea de UTF-8. En realidad no haría falta, ya que si trabajamos en Linux, esta será la codificación por defecto, por lo que sería la que utilizaría un FileReader.
1
FileReader f_ent = new FileReader("./archivos/f3.txt");
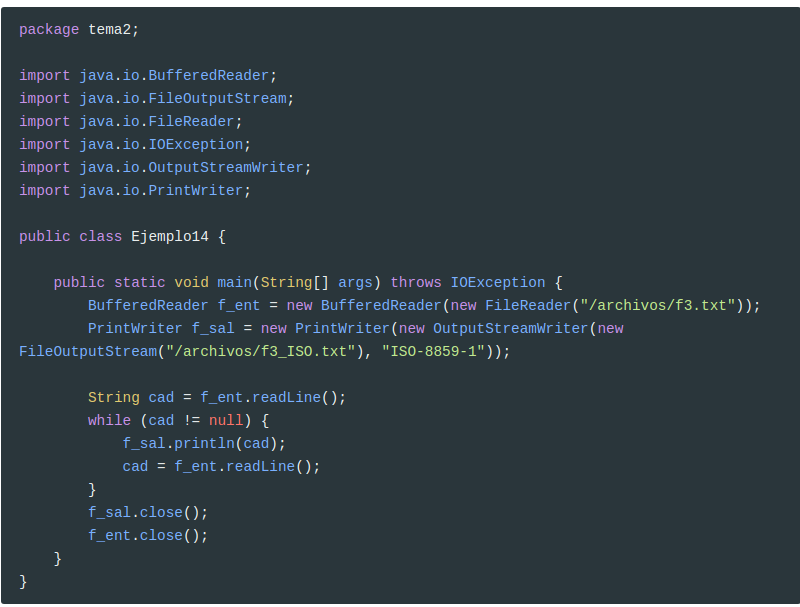
Vamos a hacer otra versión del mismo programa. Aparte de no especificar la codificación del archivo de entrada, utilizaremos los decoradores BufferedReader y PrintWriter para poder ir cómodamente línea a línea.
Ejercicio 1
Este primer ejercicio es para tratamiento de bytes, ya que se tratará de modificar una imagen.
Para poder probarlo puedes utilizar la siguiente imagen:

El formato de un archivo bmp, aproximadamente es el siguiente:
-
En los 54 primeros bytes se guarda información diversa, como el tamaño de la imagen, paleta de colores, …
-
A partir de ahí se guarda cada punto de la imagen como 3 bytes, uno para el rojo (R), uno para el verde (G) y uno para el azul (B), yendo de izquierda a derecha y de arriba bajo.
Copia y modifica la clase TransformaImagen, creando los métodos oportunos siguiendo estas pautas:
- El constructor
TransformaImagen(File fEnt)debe inicializar la propiedadf (File)si y sólo si existe el archivo y la extensión del fichero es.bmp(lo controlaremos sencillamente porque el nombre del archivo termina así). En caso contrario, sacar los mensajes de error oportunos para la salida estándar. - Los métodos de transformación (
transformaNegativo,transformaOscuroytransformaBlancoNegro) deben crear un nuevo archivo que contenga una imagen transformada como veremos más adelante. El nombre del nuevo archivo se formará a partir del nombre del archivo de entrada, que lo hemos guardado en el constructor. Será siempre poniendo antes del.bmpun guión bajo y un identificativo de la transformación realizada:_bpara el negativo,_opara el oscuro y_bnpara el blanco y negro. Es decir, si el archivo de entrada esfichero.bmp, el de salida deberá ser:fichero_n.bmppara el métodotransformaNegativofichero_o.bmppara el métodotransformaOscurofitchero_bn.bmppara el métodotransformaBlancoNegro
- En cada transformación, los primeros 54 bytes se deben copiar sin modificar: se deben escribir en el fichero de destino tal y como se han leído del archivo de entrada.
- A partir del 54, cada vez que se lee un byte, se deberá transformar antes de escribirlo en el destino. La transformación es de esta manera:
- Para el negativo (
transformaNegativo), cada byte de color (RGB) de cada punto, debe transformarse en el complementario. Como estamos hablando de bytes pero que al leer los guardamos en enteros, sencillamente será calcular 255 - b (si b es el byte leído). - Para el oscuro (
transformaOscuro), cada byte de color (RGB) de cada punto, se debe bajar de intensidad a la mitad. Sencillamente será calcular b / 2 (si b es el byte leído). - Para el blanco y negro (
transformaBlancoNegro), debemos dar el mismo valor para el rojo, el azul y el verde (RGB) de cada punto, y así conseguiremos un gris de intensidad adecuada. Una buena manera será leer los tres bytes de cada punto (no se aconseja utilizar una lectura con un array de 3 posiciones; mejor hacer tres lecturas guardadas en tres variables diferentes), calcular la media de estos 3 valores, y escribir el resultado 3 veces en el archivo de destino. Este es más complicado y se puede hacer de dos formas:- Leyendo tres bytes cada vez y guardando el valor en tres variables. Sacamos la media y guardamos el valor 3 veces.
- Leyendo los tres bytes en un array. Pero de esta forma se leen como Bytes (que internamente están en complemento a 2), por lo que si son menores que 0 hay que sumarles 256. Sacamos la media y guardamos el valor 3 veces.
- Para el negativo (
A modo orientativo de lo que se quiere hacer, os adjunto la clase TransformaImagen a la que deberás modificar el constructor y los tres métodos de transformación.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
package ejerciciostema2;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TransformaImagen {
File f = null;
public TransformaImagen(File fEnt) {
// Control de existencia del fichero y control de la extensión .bmp (sacar
// mensajes de error)
}
public void transformaNegativo() throws IOException {
// Transformar a negativo y guardar como *_n.bmp
}
public void transformaOscuro() throws IOException {
// Transformar a una imagen más oscura y guardar como *_o.bmp
}
public void transformaBlancoNegro() throws IOException {
// Transformar a una imagen en blanco y negro y guardar como *_bn.bmp
}
private String getNombreSinExtension() {
//Devuelve el nombre del archivo f sin extensión
}
}
Y también la clase main:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package ejerciciostema2;
import java.io.File;
import java.io.IOException;
public class Ejercicio2_1 {
public static void main(String[] args) throws IOException {
File f = new File("./archivos/penyagolosa.bmp");
TransformaImagen ti = new TransformaImagen(f);
ti.transformaNegativo();
ti.transformaOscuro();
ti.transformaBlancoNegro();
}
}