Ficheros con formato
Este tema servirá para finalizar el contacto con los archivos. Una vez hemos visto cómo acceder a los ficheros y a su contenido, ahora es el momento de plantearnos cómo guardar datos de diferentes tipos, como guardar objetos, …, haremos mención especial a los archivos XML y el formato JSON
- Por un lado se gestionan ficheros con datos de diferentes tipos, al contrario que en los archivos de texto, o los ejemplos que coger un fichero y tratar todos los bytes de forma igual.
- Por otra los archivos de acceso directo (también llamados de acceso relativo o aleatorio).
- También se introduce el tema de la serialización de objetos, es decir, intentar guardar objetos directamente en ficheros. Una técnica sencilla pero que tiene inconvenientes.
- Después se tratan los documentos
XMLespecíficamente, no como un archivo de texto (que lo es), sino con un tratamiento específico para poder acceder a la información jerarquizada de un documentoXML. - Y finalmente haremos lo mismo con el formato
JSON
1 Ficheros binarios con formatos específicos
DataInputStream y DataOutputStream
Ya hemos visto cómo utilizar los ficheros de caracteres y también de bytes. Pero en este último caso siempre ha sido para leer o escribir byte a byte, hasta el final de fichero.
Nos planteamos ahora cómo utilizar los archivos para guardar datos estructurados de tipos básicos diferentes. De momento no serán complicadas pero enseguida veremos que nos hace falta algo para poder trabajar cómodamente.
Supongamos un ejemplo de una empresa que quiere guardar datos de sus empleados. Concretamente quiere guardar el número de empleado, el nombre, el departamento al que pertenece, la edad y el sueldo.
| Número | Nombre | Departamento | Edad | Sueldo |
|---|---|---|---|---|
| 1 | Andreu | 10 | 32 | 1.000,00 |
| 2 | Bernat | 20 | 28 | 1.200,00 |
| 3 | Claudia | 10 | 26 | 1.400,00 |
| 4 | Damián | 10 | 40 | 1.300,00 |
Ya se ve que los datos son de diferentes tipos. Si todo fuera de texto no habría problema. Pero si consideramos los datos como numéricos enteros o reales no nos sirven los Stream de caracteres (Reader y Writer). Por lo tanto tenemos que ir a InputStream y OutputStream, pero sería muy duro trabajar directamente con bytes. Deberíamos saber exactamente cuántos bytes ocupa cada dato: int utiliza 4 bytes; short utiliza 2 bytes, byte utiliza 1 byte, y long utiliza 8 bytes; en el caso de los reales, float utiliza 4 bytes y double utiliza 8 bytes. Demasiada variedad y demasiado trabajo recordarlos todos. Nos falta pues una ayuda para poder guardar y recuperar datos de estos diferentes tipos.
Esta funcionalidad nos la proporciona la pareja DataInputStream y DataOutputStream, que son decoradores de Stream y que disponen de métodos para guardar o recuperar datos de diferentes tipos, sin tener que saber el formato interno de cada uno ni cuántos bytes ocupan. En la siguiente tabla tenemos varios métodos de estos:
| DataInputStream | Explicación | DataOutputStre |
|---|---|---|
byte readByte() |
Un byte | byte writeByte() |
short readShort() |
Un entero pequeño (2 bytes) | short writeShort() |
int readInt() |
Un entero (4 bytes) | int writeInt() |
long readLong() |
Un entero largo (8 bytes) | void writeLong(long) |
float readFloat() |
Un real de precisión simple | void writeFloat(float) |
double readDouble() |
Un real de doble precisión | void writeDouble(double) |
char readChar() |
Un carácter Unicode (16 bits) | void writeChar(char) |
String readUTF() |
Una cadena de caracteres UTF-8 y la convierte a String (16 bits) | void writeUTF(String) |
Vamos a ver un ejemplo, en el que guardaremos en un fichero llamado Empleados.dat los datos de los 4 empleados. Para comodidad nos los definiremos en arrays de 4 elementos: un array para los nombres, otro para los departamentos, etc.
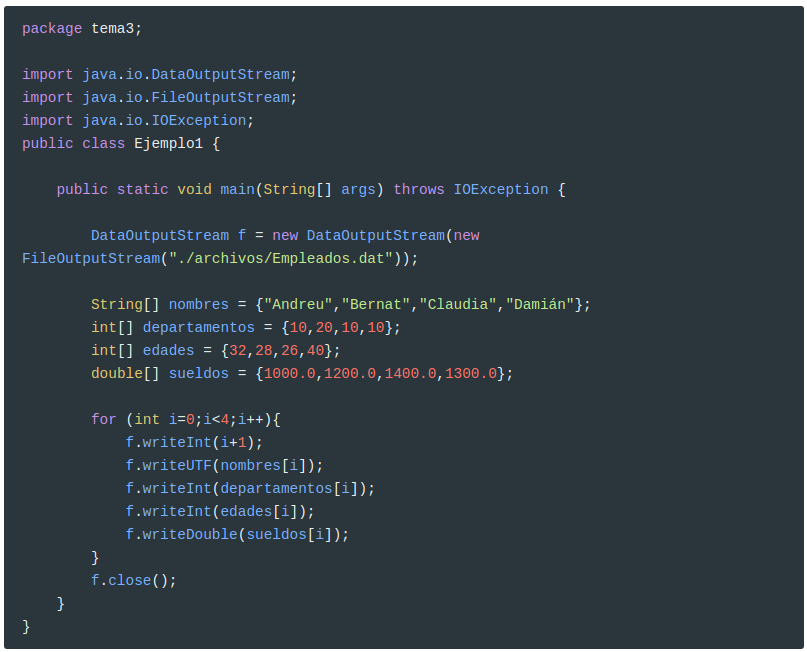
Y esta sería la recuperación de los datos:
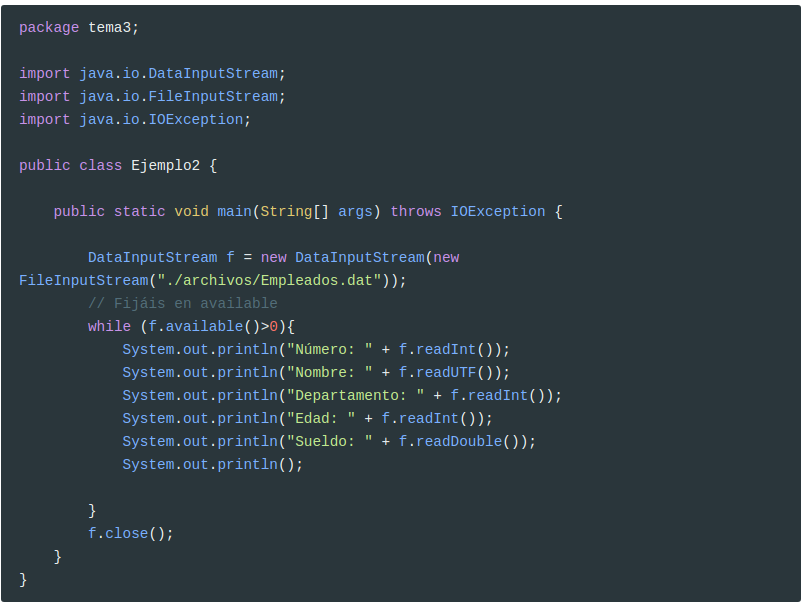
2 Acceso directo a ficheros
Los ejemplos del apartado anterior nos pueden hacer reflexionar sobre otro tipo de acceso a los ficheros. De momento todos los accesos que hemos hecho a los ficheros, tanto binarios como de carácter, han sido secuenciales. Esto quiere decir que siempre empezamos por el principio del archivo hasta que llegamos a la información que queremos, o en la mayor parte de los casos hasta el final de fichero.
Pero, ¿y si queremos únicamente una determinada información? En el ejemplo del apartado anterior, ¿qué deberíamos hacer si queremos sólo la información de la empleada 3 (Claudia)? Pues deberíamos pasar primero por todos los anteriores. Como sólo hay 2 delante, no parece mucho trabajo, pero es fácil de ver la dificultad (o mejor dicho el coste) si el archivo constara de cientos o miles de empleados. Supongamos un fichero de 10.000 empleados. Si queremos acceder al empleado 9.500 deberíamos pasar por los 9.499 empleados anteriores, ya que el acceso secuencial obliga a empezar por el principio e ir pasando hasta que encontramos la información. Y aún peor: y si después de consultar el empleado 9.500 ahora queremos consultar el 9.000? Pues deberíamos empezar desde el principio, porque ya nos lo habíamos pasado.
Afortunadamente hay otra manera de acceder, otro tipo de acceso. Se denomina acceso directo porque permitirá ir directamente a una posición determinada del archivo. Muchas veces también se llama acceso relativo o acceso aleatorio, pero el funcionamiento siempre es el mismo. Y mirad que estamos hablando de acceso. Por lo tanto lo que cambiará no es la clase File sino la que permite acceder al contenido, es decir las clases de flujo de información (los Streams).
Las clases InputStream-OutputStream y Reader-Writer sólo permiten el acceso secuencial. Por lo tanto para el acceso directo dispondremos de otra clase que nos permitirá hacer todas las operaciones, tanto de lectura como de escritura. Tiene la ventaja de que dispone de muchos métodos para poder acceder a la información. No nos hará falta, por tanto, las clases “decoradoras” que añaden funcionalidades. Con esta clase tendremos suficiente.
RandomAccessFile
La clase RandomAccessFile nos permitirá acceder de forma directa a un fichero. No nos hará falta, en principio, ninguna otra clase más. Nos proporcionará toda la funcionalidad necesaria. En los constructores irán 2 parámetros. El primero hará referencia al archivo. El segundo al modo de acceso: sólo lectura (r) o lectura-escritura (rw).
1
RandomAccessFile(File fitxer, String mode) throws FileNotFoundException
1
RandomAccessFile(String fitxer, String mode) throws FileNotFoundException
En el primer caso le especificamos un File en el primer parámetro. En el segundo un String que corresponderá con el nombre del archivo.
En ambos casos, el segundo parámetro indicará el modo:
-
“r” indica sólo lectura
-
“rw” indica lectura escritura
A pesar de ser una clase completamente diferente de la jerarquía de InputStream-OutpuStream (o Read-Writer) implementa métodos que se llaman exactamente igual que los de aquellas clases, lo que hace mucho más cómoda la utilización. Los métodos más importantes son:
| Método | Explicación | Método |
|---|---|---|
int read() |
Lee/escribe un byte (aunque devuelve o se le pasa un entero) | void write(int) |
int read(byte[]) |
Lee/escribe una serie de bytes, tantos como el tamaño del array (si puede) | int write(byte[]) |
byte readByte() |
Lee/escribe un byte interpretado como un número de 8 bits con signo | void writeByte(int) |
char readChar() |
Lee/escribe un carácter | void write(char) |
int readInt() |
Lee/escribe un entero (4 bytes) | void write(int) |
short readShort() |
Lee/escribe un entero pequeño (2 bytes) | void write(short) |
long readLong() |
Lee/escribe un entero largo (8 bytes) | void write(long) |
float readFloat() |
Lee/escribe un número real en precisión simple (4 bytes) | void write(float) |
double readDouble() |
Lee/escribe un número real en precisión doble (8 bytes) | void write(double) |
String readUTF() |
Lee/escribe una cadena de caracteres (interpretada como UTF-8) | void writeUTF(string) |
void seek(long) |
Sitúa el puntero en la posición, medido desde el princicio del fichero | |
long length() |
Devuelve el tamaño del fichero | |
void close() |
Cierra el flujo de acceso directo |
En cada lectura, después de leer el puntero que apunta al archivo estará situado tras del dato leído, cualquiera que sea el tamaño.
Vamos a ver un ejemplo utilizando el fichero Empleados.dat creado en el apartado anterior. Abrimos el acceso directo únicamente en modo lectura, y nos situamos directamente a la posición 56, que es donde comienza la información de la empleada 3 (Claudia). Posteriormente utilizamos el método de lectura apropiado para cada tipo de dato.
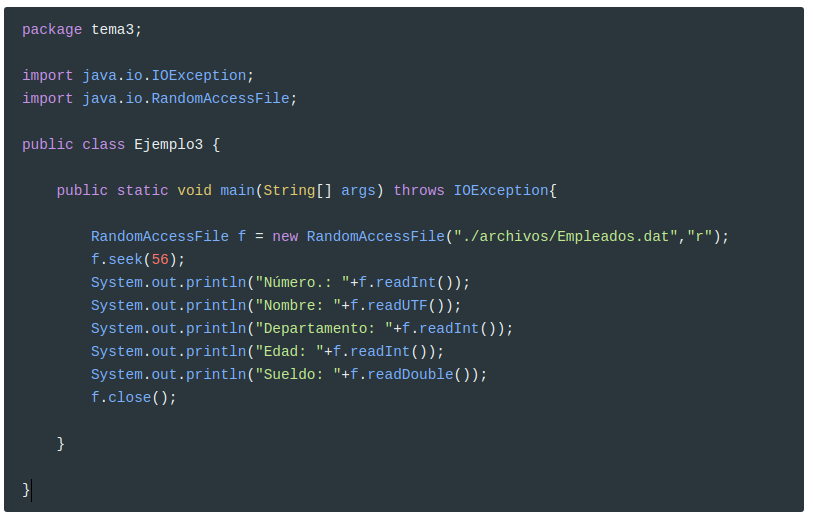
Rápidamente observamos una cosa: ¿cómo sabíamos que teníamos que situar en la posición 56? Y si los nombres de los dos primeros hubieran sido más largos o más cortos?
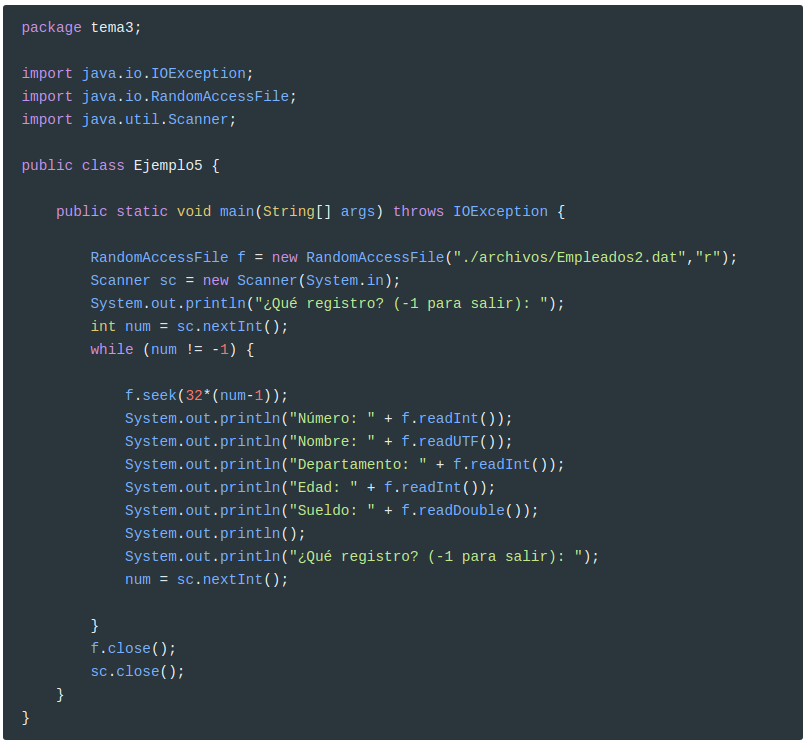
Para poder solucionar los problemas anteriores, podríamos hacer que los nombres sean de longitud fija. Los otros datos no dan problemas. Intentaremos ahora dar siempre un tamaño de 10 caracteres a cada nombre (si sospechamos que no tenemos suficiente, deberíamos hacerlos más grandes). Vamos a crear el archivo Empleados2.dat, y será exactamente igual al del anterior apartado, salvo que en el momento de poner los nombres (en un array de strings) ponemos exactamente 10 caracteres, llenando con blancos si es necesario. Evidentemente, esta no es la única manera, pero para los pocos datos que tenemos, sí la más rápida.
1
String[] nombres = {"Andreu ","Bernat ","Claudia ","Damián "};
La sentencia anterior es la única diferencia respecto al programa de creación de Empleados.dat de la pregunta anterior, además del nombre del fichero, que ahora será Empleados2.dat:
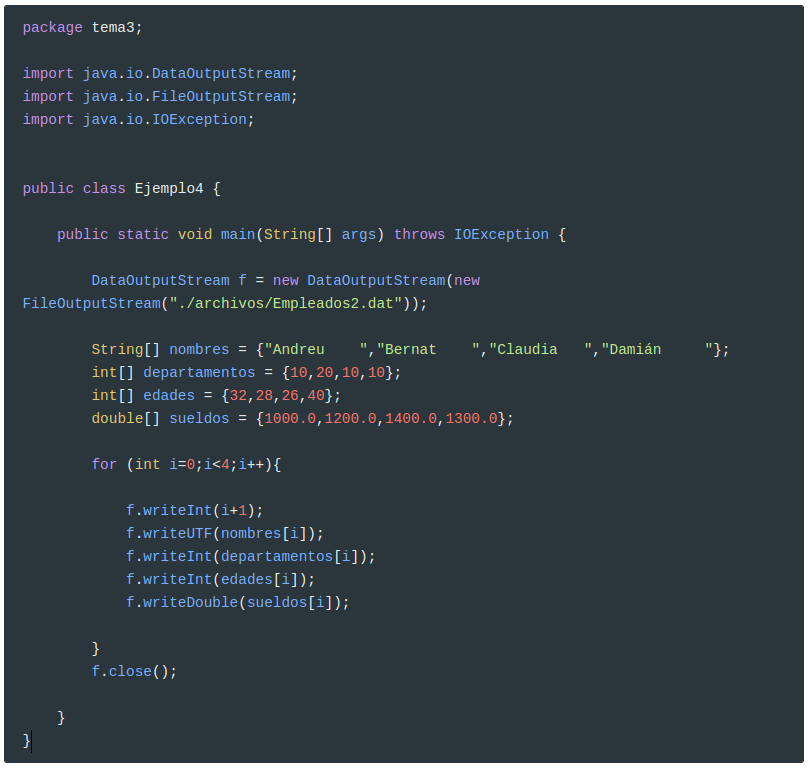
Ahora que sabemos el tamaño exacto del nombre, podemos saber que la información de cada empleado es:
| Dato | Bytes |
|---|---|
| Número de empleado (entero) | 4 bytes |
| Nombre (10 caracteres + 2 caracteres para guardar la longitud de la cadena) | 12 bytes |
| Departamento (entero) | 4 bytes |
| Edad (entero) | 4 bytes |
| Sueldo (dobre precisión) | 8 bytes |
| Total | 32 bytes |
Sabiendo que cada registro (la información de cada empleado) ocupa 32 bytes, parece fácil ir a un determinado empleado. Para poder probarlo bien, introduciremos el número de empleado por teclado, hasta introducir 0. Obsérvese que si se introduce 1, tenemos que ir a por el primer registro, que está a principio de archivo. Si introducimos 2, vamos a por el segundo, que sólo tiene uno delante, por tanto 32 bytes.
El problema ahora también parece obvio. Hemos asumido que cada carácter ocupa un byte. Como se codificará en UTF-8, mientras sean caracteres normales así será. Pero , ¿qué pasará cuando haya un carácter acentuado? Que ocupará 2 caracteres. Así, como Damián tiene uno de estos caracteres, la cadena no ocupará 10 + 2 = 12 bytes, sino 13. Entonces, si añadimos un empleado después de Damián e intentamos acceder a este registro, nos dará problemas.
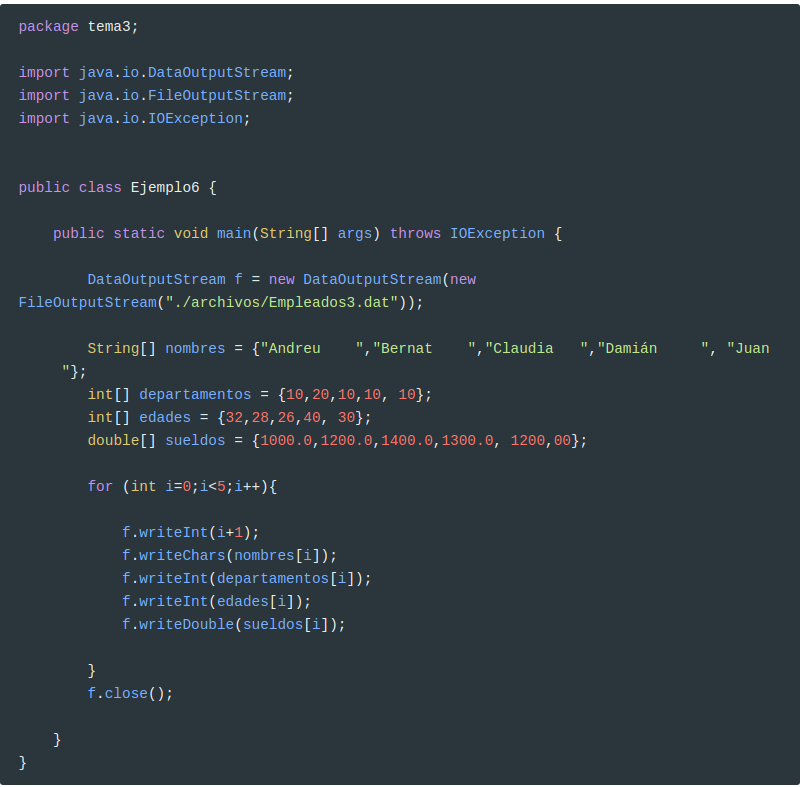
La manera de solucionarlo será escribir de manera que todos los caracteres ocupen siempre lo mismo. Hay un método que nos lo permite: writeChars. Guardará cada carácter con dos bytes, y no se guardará la longitud de la cadena. Podemos intentar utilizarlo para construir el archivo Empleados3.dat. Sólo tendremos que sustituir la siguiente sentencia:
1
f.writeChars(nombres[i]);
aparte del nombre del fichero, claro:
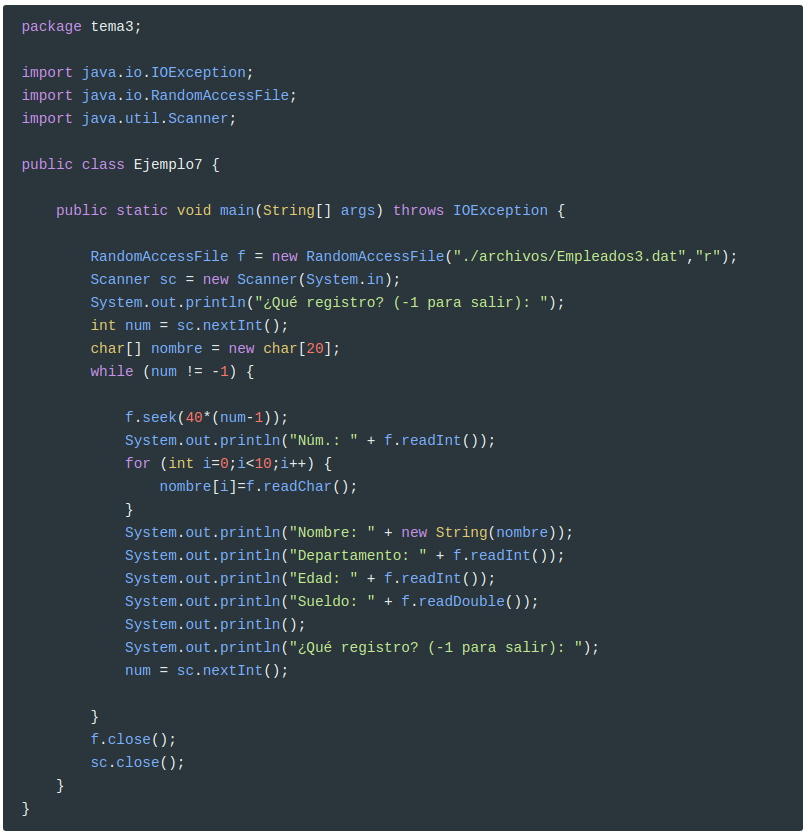
Lamentablemente la lectura no es tan fácil. Tendremos que leer exactamente 10 caracteres (podríamos utilizar algún otro método, pero lo que se muestra permite identificar claramente que se leerán 10 caracteres). Los iremos poniendo en un array de caracteres, y luego lo convertimos a String para poder mostrarlo. Se utiliza el constructor (new String(char[])), porque el método toString de un array de caracteres no tan fino. Recuerda también que ahora el nombre ocupa 20 bytes, que sumados a los otros 20 de los otros datos hacen un total de 40 bytes por registro.
Serialización de objetos
La técnica de la serialización es seguramente la más sencilla de todas, pero también a la vez la más problemática. Java dispone de un sistema genérico de serialización de cualquier objeto, un sistema recursivo que se repite para cada objeto contenido en la instancia que se está serializando. Este proceso para al llegar a los tipos primitivos, los cuales se guardan como una serie de bytes. Aparte de los tipos primitivos, Java serializa también mucha información adicional o metadatos específicas de cada clase (el nombre de las clase, los nombres de los atributos y mucha más información adicional). Gracias a los metadatos se hace posible automatizar la serialización de forma genérica con garantías de recuperar un objeto tal como se guardó.
Lamentablemente, este es un procedimiento específico de Java. Es decir, no es posible recuperar los objetos serializados desde Java utilizando otro lenguaje. Por otra parte, el hecho de guardar metadatos puede llegar a comportar también problemas, aunque utilizamos siempre el lenguaje Java. La modificación de una clase puede hacer variar sus metadatos. Estas variaciones pueden dar problemas de recuperación de instancias que hayan sido guardadas con algunas versiones anteriores a la modificación, impidiendo que el objeto pueda ser recuperado.
Estas consideraciones desestiman esta técnica para guardar objetos de forma más o menos permanente. En cambio, su sencillez la hace una perfecta candidata para el almacenamiento temporal, por ejemplo dentro de la misma sesión.
Para que un objeto pueda ser serializado es necesario que su clase y todo su contenido implementan la interfaz Serializable. Se trata de una interfaz sin métodos, porque el único objetivo de la interfaz es actuar de marcador para indicar a la máquina virtual qué clases se pueden serializar y cuáles no.
Todas las clases equivalentes a los tipos básicos ya implementan Serializable. También implementan esta interfaz la clase String y todos los contenedores y los objetos Array. La serialización de colecciones depende en último término de los elementos contenidos. Si estos son serializables, la colección también lo será.
En caso de que la clase del objeto que se intente serializar, o las de alguno de los objetos que contenga, no implementaron la interfaz Serializable, se lanzaría una excepción de tipo NotSerializableException, impidiendo el almacenamiento.
Los Streams ObjectInputStream y ObjectOutputStream son decoradores que añaden a cualquier otro Stream la capacidad de serializar cualquier objeto Serializable. El stream de salida dispondrá del método writeObject y el stream de entrada, el método de lectura readObject.
El método readObject sólo permite recuperar instancias que sean de la misma clase que la que se guardó. En caso contrario, se lanzaría una excepción de tipo ClassCastException. Además, es necesario que la aplicación disponga del código compilado de la clase; de no ser así, la excepción lanzada sería ClassNotFoundException.
Ejemplo
Nos apoyaremos en un ejemplo basado en los anteriores, en los empleados. Ahora vamos a suponer que los empleados son objetos, e intentaremos guardar estos objetos en un fichero con una serialización.
El primer paso será construir la clase Empleado, que contendrá la misma información que en los otros apartados: número de empleado, nombre, departamento, edad y sueldo. Aparte de las propiedades para cada una de los datos anteriores (que serán del mismo tipo que en las otras ocasiones), también haremos el constructor que inicializa el objeto, así como los métodos get para cada una de las propiedad. No necesitaremos los métodos set, ya que en los ejemplos siempre utilizaremos el constructor. Obsérvese como la clase debe implementar Serializable.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
package tema3;
import java.io.Serializable;
public class Empleado implements Serializable {
/**
* Versión 1. serialVersionUID sirve para asegurarnos que serializamos/deserializamos
* objetos de la misma versión (puede que entre versiones haya cambiado la signatura de la
* clase y nos dé errores. Cuando cambia la signatura se debe modificar este valor
*/
private static final long serialVersionUID = 1L;
private int num=0;
private String nombre=null;
private int departamento=0;
private int edad=0;
private double sueldo=0.0;
public Empleado(){
}
public Empleado(int num, String nombre, int departamento, int edad, double sueldo){
this.num = num;
this.nombre = nombre;
this.departamento = departamento;
this.edad = edad;
this.sueldo = sueldo;
}
public int getNum(){
return this.num;
}
public String getNombre(){
return this.nombre;
}
public int getDepartamento(){
return this.departamento;
}
public int getEdad(){
return this.edad;
}
public double getSueldo(){
return this.sueldo;
}
}
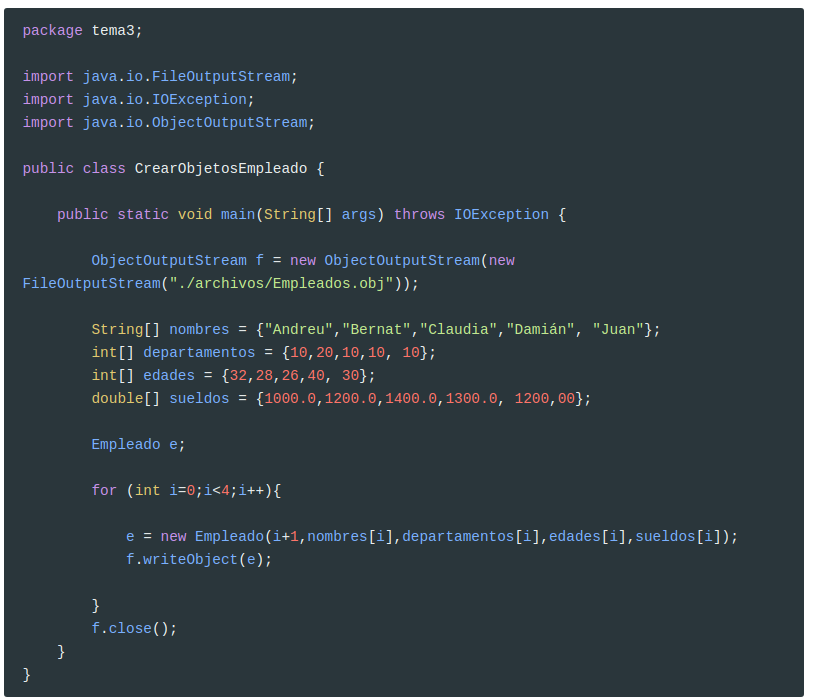
Vamos a intentar construir el archivo. El flujo de datos será un ObjectOutputStream para poder escribir (writeObject). Y observa cómo se debe apoyar en un OutputStream, que en este caso será de un archivo, es decir un FileOutputStream. En cada iteración del bucle sencillamente construir un objeto de la clase Empleado y lo escribiremos en el archivo.
Nota
El fichero creado,
Empleados.obj, evidentemente no es de texto. Sin embargo si lo abrimos con un editor de texto podremos ver alguna cosa.
- La primera cuestión es que se guarda el nombre de la clase con el nombre del paquete delante. tema3.Empleado es realmente el nombre de la clase creada.
- Se guardan también los nombres de los campos. Todo esto son los metadatos que habíamos comentado, y que permiten la recuperación posterior de los objetos guardados
- Y luego ya podemos ver la información guardada, donde identificamos los nombres de los empleados

Para leer el archivo creado, Empleados.obj, utilizaremos el ObjectInputStream para poder hacer readObject. Debe basarse en un InputStream, que en este caso será un FileInputStream. El tratamiento de final de archivo lo haremos capturando la excepción (el error) de haber llegado al final y intentado leer aún: EOFException. La razón es que readObject no vuelve null, a no ser que se haya introducido este valor. Por tanto montamos un bucle infinito, pero capturando con try ... catch el error, que es cuando cerraremos el Stream.
Para comprobar cómo funciona serialVersionUID, vamos a añadir un campo más a la clase Empleado.java y a aumentar este número.
1
2
3
4
5
6
7
8
9
10
11
12
public class Empleado implements Serializable {
/**
* Versión 2. Hemos cambiado la clase añadiendo un nuevo campo y por eso le ponemos versión 2
*/
private static final long serialVersionUID = 2L;
private int num=0;
private String nombre=null;
private int departamento=0;
private int edad=0;
private double sueldo=0.0;
private String localidad = null;
Si ahora pretendemos ejecutar LeerObjetosEmpleado.java, producirá la excepción InvalidClassException
1
2
3
4
5
6
7
8
9
Exception in thread "main" java.io.InvalidClassException: tema3.Empleado; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:687)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1880)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1746)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2037)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1568)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:428)
at tema3.LeerObjetosEmpleado.main(LeerObjetosEmpleado.java:17)
4 Documentos XML
Hemos visto que la manera más cómoda de guardar objetos es con la serialización, por medio del ObjectInputStream y ObjectOutputStream, pero que fuera de Java no es posible el acceso a estos datos. Y también dentro de Java podemos tener problemas, porque el nombre de la clase con el nombre del paquete se guarda en el archivo como metadatos, y en otro programa deberemos tener la clase creada en un paquete con el mismo nombre, sino no se podrán recuperar los datos.
También hemos visto que para guardar datos individuales de diferentes tipos nos van muy bien las clases DataInputStream y DataOutputStream, pero tendremos que saber muy bien el orden y tipo de datos que están guardados, sino, no las podremos recuperar.
Y no entramos ya en la posibilidad de que diferentes Sistemas Operativos representan la información de forma diferente (por ejemplo, hay Sistemas Operativos que representan los números con BCD y otros que utilizan complemento a 2).
Por lo tanto, cuando queramos guardar datos que puedan ser leídas por aplicaciones hechas en diferentes lenguajes y/o ejecutadas en diferentes plataformas, nos hará falta un formato estándar que todos lo puedan entender y reconocer, y mejor si es autoexplicativo como es el caso de los lenguajes de marcas. El lenguaje de marcas más conocido y más utilizado es el XML (eXtensible Markup Language).
Los documentos XML consiguen estructurar la información intercalando unas marcas denominadas etiquetas, cada etiqueta con un principio y un final, y que pueden ir unas dentro de otras, y también contener información de texto. De este modo, se podrá subdividir la información estructurando de forma que pueda ser fácilmente interpretada.
Toda la información será de texto, y por tanto no habrá el problema mencionado antes de representar los datos de diferente manera. Cualquier dato, ya sea numérico, booleano o como sea, se pondrá en modo texto, y por tanto siempre se podrá leer e interpretar correctamente toda la información contenida en un archivo XML.
Es cierto que los caracteres se pueden escribir utilizando diferentes sistemas de codificación, pero XML ofrece diversas técnicas para evitar que esto sea un problema, como por ejemplo, incluyendo a la cabecera del archivo que codificación se ha utilizado en el momento de guardar el.
Con las etiquetas, XML consigue estructurar cualquier tipo de información jerárquica. Se puede establecer cierta similitud entre la forma como la información se guarda en los objetos de una aplicación y la forma como se guardaría en un documento XML. La información, en las aplicaciones orientadas a objetos, se estructura, agrupa y jerarquiza en clases, y en los documentos XML se estructura, organiza y jerarquiza en etiquetas contenidas unas dentro de otras y atributos de las etiquetas.
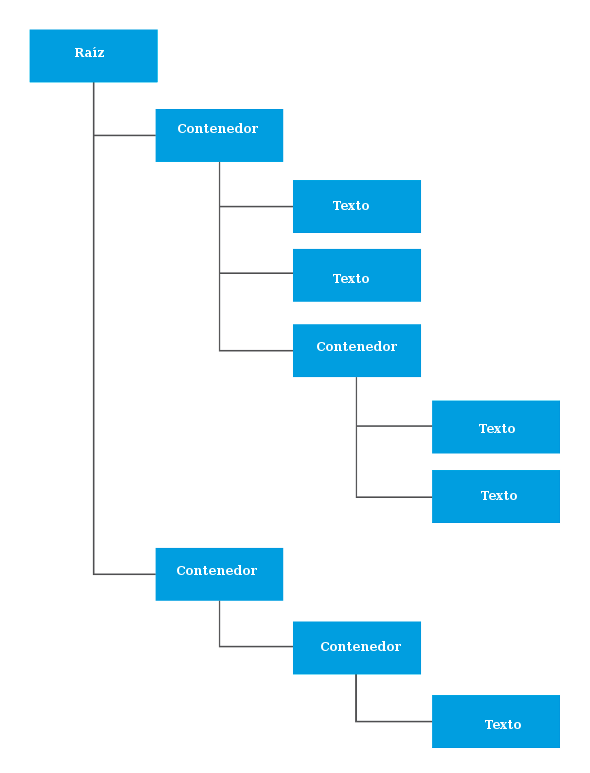
Imaginemos que queremos representar los datos de los empleados como los del aparato anterior utilizando un formato XML. No existe una única solución, pero es necesario que todas respetan la jerarquía del modelo. Un posible formato podría ser el siguiente:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
<empresa>
<empleado>
<num>1</num>
<nombre>Andreu</nombre>
<departamento>10</departamento>
<edad>32</edad>
<sueldo>1000.0</sueldo>
</empleado>
<empleado>
<num>2</num>
<nombre>Bernat</nombre>
<departamento>20</departamento>
<edad>28</edad>
<sueldo>1200.0</sueldo>
</empleado>
<empleado>
<num>3</num>
<nombre>Claudia</nombre>
<departamento>10</departamento>
<edad>26</edad>
<sueldo>1400.0</sueldo>
</empleado>
<empleado>
<num>4</num>
<nombre>Damián</nombre>
<departamento>10</departamento>
<edad>40</edad>
<sueldo>1300.0</sueldo>
</empleado>
<empleado>
<num>5</num>
<nombre>Juan</nombre>
<departamento>10</departamento>
<edad>40</edad>
<sueldo>1200.0</sueldo>
</empleado>
</empresa>
Pero esta también podría ser una manera de representarlo:
1
2
3
4
5
6
7
<empresa>
<empleado num='1' nombre='Andreu' departamento='10' edad='32' sueldo='1000.0'/>
<empleado num='2' nombre='Bernat' departamento='20' edad='28' sueldo='1200.0'/>
<empleado num='3' nombre='Claudia' departamento='10' edad='26' sueldo='1400.0'/>
<empleado num='4' nombre='Damián' departamento='10' edad='40' sueldo='1300.0'/>
<empleado num='5' nombre='Juan' departamento='10' edad='40' sueldo='1200.0'/>
</empresa>
Y podemos imaginar muchas otras soluciones, combinando como atributos o subetiquetas las diferentes características de los empleados que queremos guardar. Este sería el problema principal del XML, las múltiples soluciones (hay estándares basados dtd). Pero también es verdad que todas ellas son fáciles de entender.
4.1 Parser o analizador XML
Un Parser XML es una clase que nos permite analizar y clasificar el contenido de un archivo XML extrayendo la información contenida en cada una de las etiquetas, y relacionarla de acuerdo con su posición en la jerarquía. Hay dos tipos de analizadores dependiendo del modo de funcionar.
4.1.1 Analizadores secuenciales
Los analizadores secuenciales permiten extraer el contenido a medida que se van descubriendo las etiquetas de apertura y cierre. También se denominan analizadores sintácticos. Son analizadores muy rápidos, pero presentan el problema de que cada vez que se necesita acceder a una parte del contenido se debe releer todo el documento de arriba a abajo. En Java, el analizador sintáctico más popular se llama SAX, que significa Simple API for XML. Es una analizador muy utilizado en varias bibliotecas de tratamiento de datos XML, pero no suele utilizarse en aplicaciones finales, por el problema antes comentado de tener que leerse todo el documento XML en cada consulta. Por esta razón no los veremos en este curso.
4.1.2 Analizadores jerárquicos
Generalmente, las aplicaciones finales que deben trabajar con datos XML suelen utilizar analizadores jerárquicos.
Los analizadores jerárquicos guardan todos los datos del documento XML en memoria dentro de una estructura jerárquica, a medida que van analizando su contenido. Y por eso son ideales para aplicaciones que requieren una consulta continua de los datos.
El formato de la estructura donde se guarda la información en memoria ha sido especificado por el organismo internacional W3C (World Wide Web Consortium) y se conoce como DOM (Document Object Model). Es una estructura que HTML y javascript han popularizado mucho y se trata de una especificación que Java materializa en forma de interfaces. La principal se denomina Document y representa todo un documento XML. Al tratarse de una interfaz, puede ser implementada por varias clases.
El estándar W3C define la clase DocumentBuilder (constructor de documentos) para poder crear estructuras DOM a partir de un XML. Esta clase DocumentBuilder es una clase abstracta, y para que se pueda adaptar a las diferentes plataformas, puede necesitar fuentes de datos o requerimientos diversos. Recuerda que las clases abstractas no se pueden instanciar de forma directa. Por este motivo, el consorcio W3 especifica también la clase DocumentBuilderFactory, es decir, el fabricante de DocumentBuilder.
Las librerías desde donde importaremos las clases comentadas son:
-
DocumentBuilderFactoryyDocumentBuilderlas importaremos de la librería javax.xml.parsers.* -
Documentla importaremos de org.w3c.dom.*
Debemos cuidar sobre todo esta última importación, porque por defecto Java nos ofrece muchas librerías desde donde importar Document. Y si no la importamos de la librería correcta, evidentemente después tendremos errores. Las instrucciones necesarias para leer un archivo XML y crear un objeto Document serían las siguientes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import java.io.FileInputStream;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
...
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(new File("fichero.xml"));
Volvemos a insistir en la necesidad de importar Document de la librería org.w3c.dom.*
Vamos a basarnos en un ejemplo para poder ver poco a poco la manera de utilizar el parser. Supondremos que está en el archivo coches.xml, y que está en el directorio del proyecto donde haremos las pruebas.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
<?xml version="1.0" encoding="UTF-8"?>
<oferta>
<vehiculo>
<marca>ford</marca>
<modelo color="gris">focus</modelo>
<motor combustible="gasolina">duratorc 1.4</motor>
<matricula>1234AAA</matricula>
<kilometros>12500</kilometros>
<precio_inicial>12000</precio_inicial>
<precio_oferta>10000</precio_oferta>
<extra valor="250">pintura metalizada</extra>
<extra valor="300">llantas</extra>
<foto>11325.jpg</foto>
<foto>11326.jpg</foto>
</vehiculo>
<vehiculo>
<marca>ford</marca>
<modelo color="gris">focus</modelo>
<motor combustible="diesel">duratorc 2.0</motor>
<matricula>1235AAA</matricula>
<kilometros>125000</kilometros>
<precio_inicial>10000</precio_inicial>
<precio_oferta>9000</precio_oferta>
<extra valor="250">pintura metalizada</extra>
<extra valor="200">spoiler trasero</extra>
<extra valor="500">climatizador</extra>
<foto>11327.jpg</foto>
<foto>11328.jpg</foto>
</vehiculo>
</oferta>
Lo primero que haremos será intentar conectar con este archivo, pero de una forma un poco más reducida que antes, sin definir objetos del DocumentBuilderFactory ni DocumentBuilder. Tampoco necesitaremos definirnos el File(FileInputStream) ya que el método parse también coge un String como parámetro:
1
2
3
4
5
6
7
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
...
Document doc = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse("./archivos/coches.xml");
Pero, ¿y si el proceso que necesitamos es el inverso? Es decir, y si lo que queremos es guardar una estructura DOM en un fichero XML?
En este caso lo que tendremos que hacer será construir un documento vacío, ir poniendo los elementos y atributos (con sus valores) de alguna manera, y posteriormente guardarlo en un archivo. Dejamos para un poco más adelante como ir construyendo los nodos del documento y centrémonos en el hecho de crear el documento vacío y guardarlo en un archivo. Podemos construir un documento nuevo a partir del DocumentBuilder, utilizando el método newDocument():
1
2
3
4
5
6
7
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
...
Document doc1 = DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument();
Para escribir la información contenida en el DOM en un fichero, se puede hacer usando otra utilidad de Java llamada Transformer. Se trata de una utilidad que permite realizar fácilmente conversiones entre diferentes representaciones de información jerárquica. Es capaz, por ejemplo, de pasar la información contenida en un objeto Document a un archivo de texto en formato XML. También sería capaz de hacer la operación inversa, pero no vale la pena porque el mismo DocumentBuilder ya se encarga de ello. Transformer es también una clase abstracta y requiere de una factory para poder ser instanciada. La clase Transformer puede trabajar con multitud de contenedores de información porque en realidad trabaja con un par de tipos adaptadores (clases que hacen compatibles jerarquías diferentes) que se llaman Source y Result. Las clases que implementan estas interfaces se encargarán de hacer compatible un tipo de contenedor específico al requerimiento de la clase Transformer. Así, disponemos de las clases DOMSource, SAXSource o StreamSource como adaptadores del contenedor de la fuente de información (DOM, SAX o Stream respectivamente). DOMResult, SAXResult o StreamResult son los adaptadores equivalentes del contenedor destino. A nosotros ahora, como lo que queremos pasar un documento DOM a un fichero, nos convendrá un DOMSource y un StreamResult
El código básico para realizar una transformación de DOM archivo de texto XML sería el siguiente:
1
2
3
4
5
6
7
8
9
10
11
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
...
Transformer trans = TransformerFactory.newInstance().newTransformer();
DOMSource source = new DOMSource(doc);
StreamResult result = new StreamResult(file);
trans.transform(source, result);
De todas formas, veremos más adelante un ejemplo donde nos guardaremos una estructura DOM en un archivo XML.
4.2 La estructura DOM
La estructura DOM toma la forma de un árbol, donde cada parte del XML se encontrará representada en forma de nodo. En función de la posición en el documento XML, hablaremos de diferentes tipos de nodos:
-
El nodo principal que representa todo el
XMLentero denominaDocument. -
Las diversas etiquetas, incluida la etiqueta raíz, se conocen como nodos
Element. -
El contenido de una etiqueta de tipo texto, será un nodo de tipo
TextElement -
Los atributos serán nodos de tipo
Attribute.
Cada nodo específico dispone de métodos para acceder a sus datos concretos (nombre, valor, nodos hijos, nodo padre, etc.). Es decir, que el nodo sirve para situarse en una determinada posición (elemento, atributo, elemento de texto, …). Tendrá unos métodos, sobre todo para navegar, aunque también algunos para sacar el contenido. Element es un clase derivada de Node (por tanto hereda todos sus métodos), y proporciona algunas cosas más, sobre todo para acceder cómodamente a sus partes. Miremos los métodos más importantes, tanto de Node como de Element y Document.
Métodos de Node
| Valor devuelto | Método | Explicación |
|---|---|---|
| String | getNodeName() |
El nombre del nodo |
| short | getNodeType() |
El tipo de este nodo (ELEMENT_NODE, ATTRIBUTE_NODE, TEXT_NODE, …) |
| String | getNodeValue() |
El valor del nodo, si tiene |
| NodeList | getChildNodes() |
Una lista con todos los hijos |
| Node | getFirstChild() |
El primer hijo |
| Node | getLastChild() |
El último hijo |
| NamedNodeMap | getAttributes() |
Una lista con los atributos del nodo (null si no tiene ninguno) |
| Node | getParentNode() |
El padre |
| String | getTextContent() |
El texo contenido en el elemento y el de todos sus descendientes si tiene. |
| boolean | hasChildNodes() |
Devuelve true si el nodo tiene algún hijo |
| boolean | hasAttributes() |
Devuelve true si tiene algún atributo |
Métodos de Element
| Valor devuelto | Método | Descripción |
|---|---|---|
| String | getAttribute(String nombre) |
Devuelve el valor del atributo que tiene este nombre |
| NodeList | getElementsByTagName(String nombre) |
Devuelve una lista de nodos con todos los descendientes que tienen este nombre de tag |
| boolean | hasAttribute() |
Devuelve true si el elemento tiene este atributo |
Siempre que tengamos una lista de nodos, podremos acceder a cada uno de los miembros de la lista con el método item() especificando el número de orden. Así, si queremos acceder al primer pondremos item(0) Posteriormente pondremos los métodos que sirven para ir poniendo contenido en un documento: crear hijos, crear atributos, poner contenido, … El DOM resultante obtenido desde un XML acaba siendo un copia exacta del archivo, pero dispuesto de diferente manera. Tanto el XML como el DOM habrá información no visible, como los retornos de carro, a tener en cuenta para saber procesar correctamente el contenido y evitar sorpresas poco comprensibles. Para ilustrar el problema que pueden suponer los retorno de carro, imaginemos que disponemos de un documento XML con el siguiente contenido:
1
2
3
4
5
6
<table>
<tr>
<td> </td>
<td> </td>
</tr>
</table>
Veremos más claro si representamos los retorno de carro en el mismo documento:
1
2
3
4
5
6
<table>¶
<tr>¶
<td> </td>¶
<td> </td>¶
</tr>¶
</table>
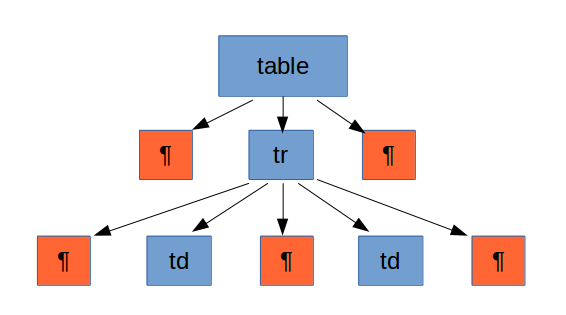
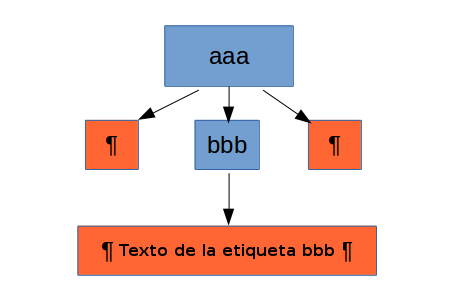
En la siguiente figura se muestra la representación que tendría el objeto DOM, un vez esté ya copiado en memoria. Observa como el elemento table tendrá tres hijos. En uno se guardará el retorno de carro que sitúa la etiqueta <tr> a la siguiente línea, en el segundo encontraremos la etiqueta <tr>, y en el tercero el retorno de carro que hace que </ table> esté en la línea de bajo. Lo mismo ocurre con los hijos de <tr>, antes y después de cada nodo <td> encontraremos un retorno de carro.
En cambio, si hubiéramos partido de un XML equivalente pero sin retornos de carro, el resultado habría sido diferente:
1
<table><tr><td></td><td></td></tr></table>
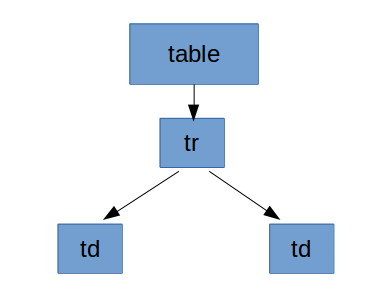
La ausencia de retornos de carro en el archivo implica también la ausencia de nodos conteniendo los retornos de carro en la estructura DOM. Otro aspecto a tener en cuenta es que el contenido de las etiquetas se plasma en el DOM como un nodo hijo de la etiqueta contenedora. Es decir, para obtener el texto de una etiqueta hay que obtener el primer hijo de ésta.
1
2
3
4
5
<aaa>
<bbb>
texto de la etiqueta bbb
</bbb>
</aaa>
4.2.1 Lectura
Vamos a hacer pruebas para comprobar el funcionamiento. Nos basamos en el documento coches.xml mencionado en la pregunta 4.1
Importante Tened cuidado, porque en el documento
coches.xmldelante la primera etiqueta no puede haber ni retorno de carro ni un espacio en blanco ni nada
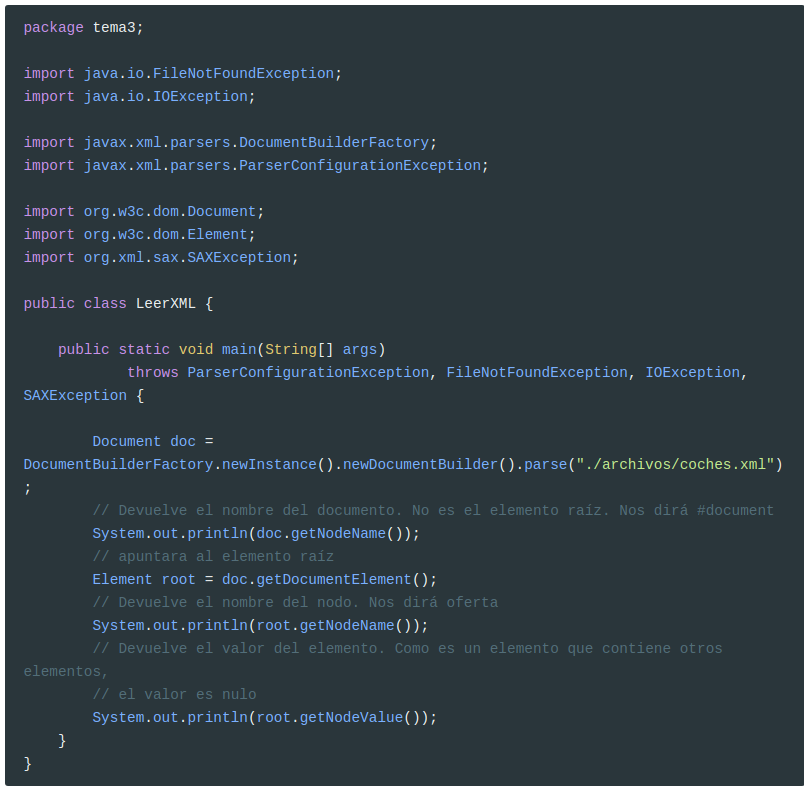
Tal y como está documentado, esta será la salida:
1
2
3
#document
oferta
null
Vamos a comprobar ahora que el primer hijo de oferta no es vehiculo sino el retorno de carro. Los elementos vehiculo son el segundo y el cuarto (índice 1 y 3)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
package tema3;
import java.io.FileNotFoundException;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class LeerXML2 {
public static void main(String[] args)
throws ParserConfigurationException,
FileNotFoundException,
IOException,
SAXException {
Document doc = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse("./archivos/coches.xml");
Element root = doc.getDocumentElement(); // apuntarà al elemento raíz
NodeList hijos = root.getChildNodes();
System.out.println(hijos.item(0).getNodeName()); // el primer hijo es el retorno de carro.
System.out.println(hijos.item(1).getNodeName()); // el segundo hijo sí que és vehiculo
System.out.println(hijos.item(2).getNodeName()); // el tercer hijo es el retorno de carro.
System.out.println(hijos.item(3).getNodeName()); // el cuarto hijo sí que és vehiculo
System.out.println(hijos.item(4).getNodeName()); // el quinto hijo es el retorno de carro.
System.out.println(hijos.item(5).getNodeName()); // no existe el sexto hijo. Dará error
}
}
Observad que en la última sentencia estamos provocando un error:
1
2
3
4
5
6
7
#text
vehiculo
#text
vehiculo
#text
Exception in thread "main" java.lang.NullPointerException
at tema3.LeerXML2.main(LeerXML2.java:29)
Por lo tanto, tenemos que tener mucho cuidado con los retornos de carro.
- Para poder esquivar los retorno de carro podríamos mirar el tipo de cada nodo (
getNodeType()), despreciar los de tipoTEXT_NODEy considerar sólo los de tipoELEMENT_NODE. - Pero normalmente el acceso que haremos será un poco más directo y más fácil. Tomaremos la lista de todos los elemento que tengan un determinado nombre con
getElementsByTagName(nombre). Evidentemente en la lista no estarán los retornos de carro y así no tendremos problemas con ellos.
En el siguiente ejemplo recorreremos todos los elemento vehiculo. De cada uno tomaremos el contenido de los elementos marca y matrícula. También tomamos el contenido del atributo combustible del elemento motor:
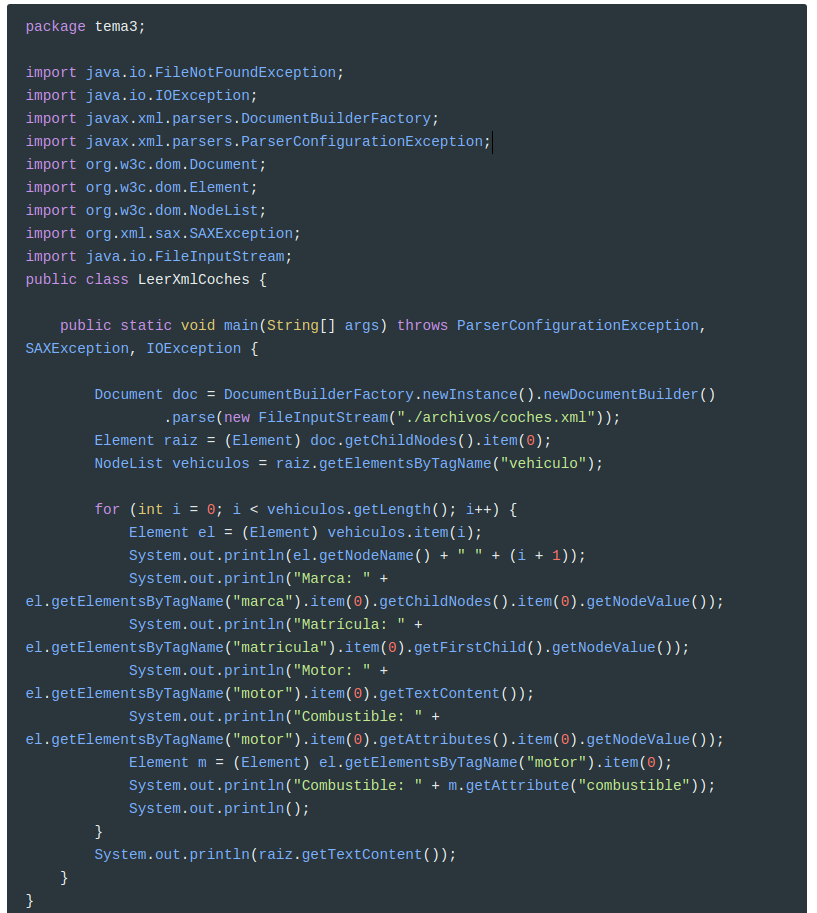
Es muy importante observar que cuando tenemos un elemento que ya tiene contenido, la información no es accesible, sino que tenemos que ir al primer hijo, que este ya es de tipo TEXT_NODE, para coger su valor.
En el ejemplo:
Varias formas de acceder al contenido
Para marca hemos cogido de toda la lista de hijos el primero, para sacar su valor.
En matricula en vez de coger toda la lista de hijos, sólo hemos tomado el primero, y por lo tanto es más rápido de escribir. Es decir:
Y para motor utilizamos el método
getTextContent, que coge el contenido de texto del elemento y de todos sus descendientes. Como es un nodo de texto ya sabemos a priori que nos irá bien, y por lo tanto es la forma más rápida.El atributo combustible del elemento motor lo hemos sacado de 2 maneras:
La primera cogiendo la lista de atributos, y luego el primero de esta lista.
En la segunda manera se ha hecho más elegante, yendo a buscar la propiedad en cuestión. Por eso hemos convertido el nodo en el elemento m, para poder utilizar
getAttribute.
Al final hacemos el getTextContent() sobre la raíz para comprobar que saca su contenido y el de todos sus hijos, por eso aparece la información duplicada Este será el resultado del ejemplo anterior:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
vehiculo 1
Marca: ford
Matrícula: 1234AAA
Motor: duratorc 1.4
Combustible: gasolina
Combustible: gasolina
vehiculo 2
Marca: ford
Matrícula: 1235AAA
Motor: duratorc 2.0
Combustible: diesel
Combustible: diesel
ford
focus
duratorc 1.4
1234AAA
12500
12000
10000
pintura metalizada
llantas
11325.jpg
11326.jpg
ford
focus
duratorc 2.0
1235AAA
125000
10000
9000
pintura metalizada
spoiler trasero
climatizador
11327.jpg
11328.jpg
4.2.2 Escritura
Vamos ahora a crear un nuevo documento XML y guardarlo en un archivo. Utilizaremos como ejemplo Empleados. Al final de todo convertiremos el archivo Empleados.obj, generado en la pregunta 3, en el fichero Empleados.xml.
La primera consideración es que partiremos de un documento vacío. Iremos construyendo los elementos y poniendo los atributos, y cuando tengamos un elemento creado por completo, lo añadiremos a la estructura, es decir haremos que sea el hijo de uno que ya está en la estructura. Podríamos hacerlo también al revés, es decir, primero colgarlo de la estructura y luego ir llenándolo.
Los principales métodos para ir construyendo la estructura son:
Métodos de Document
| Valor devuelto | Método | Descripción |
|---|---|---|
Element |
createElement(String nombre) |
Crea un elemento con el nombre indicado (se deberá colgar de la estructura) |
Text |
createTextNode(String datos) |
Crea un nuevo elemento de texto (con contenido) |
Node |
appendChild(Node nuevo) |
Añade el nodo, que será la raíz |
Métodos de Node
| Valor devuelto | Método | Descripción |
|---|---|---|
Node |
appendChild(Node nuevo) |
Añade el nodo nuevo como el último hijo hasta el momento |
void |
removeChild(Node antiguo) |
Elimina el nodo antiguo como hijo |
Métodos de Element
| Valor devuelto | Método | Descripción |
|---|---|---|
void |
setAttribute(String nombre, String valor) |
Añade el nuevo atributo al elemento, con el nombre y valor indicados |
void |
removeAttribute(String nombre) |
Elimina el atributo del elemento |
Vamos a hacer directamente ya el ejemplo de los empleados. Todos los datos serán elementos, excepto el número de empleado, que haremos que sea un atributo de empleado para practicar. Al elemento raíz le llamaremos empleados. El resultado debe ser el archivo Empleados.xml.
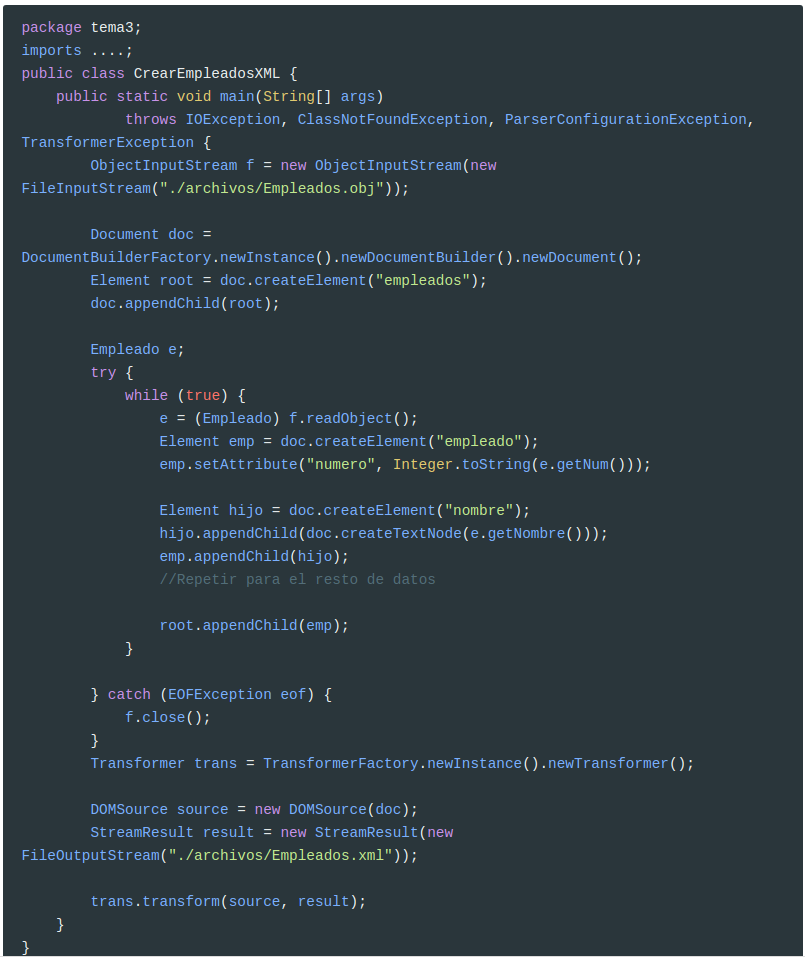
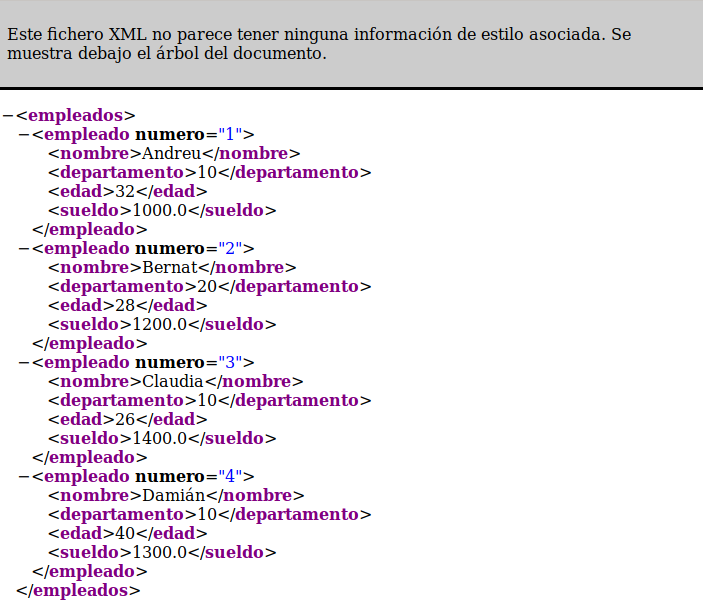
En el archivo XML generado, observarás que no hay retornos de carro, todo está en una misma línea. Si deseas verlo bien, puedes abrirlo por ejemplo con un navegador web, que interpreta bien el formato XML.
1
<?xml version="1.0" encoding="UTF-8" standalone="no"?><empleados><empleado numero="1"><nombre>Andreu</nombre><departamento>10</departamento><edad>32</edad><sueldo>1000.0</sueldo></empleado><empleado numero="2"><nombre>Bernat</nombre><departamento>20</departamento><edad>28</edad><sueldo>1200.0</sueldo></empleado><empleado numero="3"><nombre>Claudia</nombre><departamento>10</departamento><edad>26</edad><sueldo>1400.0</sueldo></empleado><empleado numero="4"><nombre>Damián</nombre><departamento>10</departamento><edad>40</edad><sueldo>1300.0</sueldo></empleado></empleados>
5 Documentos JSON
JSON significa JavaScript Object Notation, es decir Notación de Objetos de JavaScript. Es una manera de representar objetos inicialmente para javascript, pero por su sencillez, y como es en texto plano, sirve para cualquier entorno. Permite representar estructuras de datos de una determinada complejidad, como el XML, pero pesa mucho menos que éste, y por eso está convirtiéndose en un estándar de intercambio de datos, sobre todo entre un servidor y una aplicación web.
5.1 Estructura JSON
Con JSON podremos representar:
-
Valores, de tipo carácter (entre comillas dobles), numérico (sin comillas), booleano (true o false) o null.
-
Parejas clave valor, es decir un nombre simbólico acompañado de un valor asociado . Se representan así:
"nombre": valor -
Objetos, que es una colección de miembros, cada uno de los cuales puede ser una pareja clave valor, u otros objetos (incluso arrays): se representan entre llaves, y con los elementos separados por comas:
{"nombre1": " valor1 "," nombre2 ": valor2, valor 3, ...} -
Arrays, que son listas de elementos con la misma estructura. Cada elemento puede ser un valor, una pareja clave valor, un objeto o un array.
Veamos alguno ejemplos:
1
{ "p1" : 2 , "p2" : 4 , "p3" : 6 , "p4" : 8 , "p5" : 10 }
en este caso tenemos un objeto, la raíz, que tiene 5 miembros, todos ellos parejas clave-valor.
1
2
3
4
5
6
7
{
"num": 1 ,
"nombre": "Andreu" ,
"departamento": 10 ,
"edad": 32 ,
"sueldo": 1000.0
}
ahora un objeto, la raíz, también con 5 miembros que son parejas clave-valor. Obsérvese como la clave siempre la ponemos entre comillas, y el valor cuando es un string también, pero cuando es numérico, no.
1
2
3
4
5
6
7
8
{ "empleado" :
{ "num": 1 ,
"nombre": "Andreu" ,
"departamento": 10 ,
"edad": 32 ,
"sueldo": 1000.0
}
}
en este caso tenemos un objeto, la raíz que consta de un único objeto {}, empleado, el cual consta de 5 miembros clave-valor.
Miremos un ejemplo con un array:
1
2
3
{ "notas" :
[ 5 , 7 , 8 , 7 ]
}
donde tenemos el elemento raíz que consta de un único miembro, notas, que es un array [].
Y ahora uno más completo con la misma estructura que el archivo XML que habíamos visto en la pregunta 4. Tendremos un objeto raíz, con sólo un objeto, empresa, que tiene un único elemento empleado que es un array con 4 elementos, cada uno de los empleados :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
{ "empresa":
{ "empleado":
[ {
"num": "1",
"nombre": "Andreu",
"departamento": "10",
"edad": "32",
"sueldo": "1000.0"
},
{
"num": "2",
"nombre": "Bernat",
"departamento": "20",
"edad": "28",
"sueldo": "1200.0"
},
{
"num": "3",
"nombre": "Claudia",
"departamento": "10",
"edad": "26",
"sueldo": "1400.0"
},
{
"num": "4",
"nombre": "Damián",
"departamento": "10",
"edad": "40",
"sueldo": "1300.0"
}
]
}
Como ejemplo real, un WebService de Google Maps nos proporciona información de los sitios que encuentra cerca, entre otras cosas la dirección, de unas coordenadas que le pasamos (en el ejemplo 40, 0). Por ejemplo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
{
"results" : [
{
"address_components" : [
{
"long_name" : "31",
"short_name" : "31",
"types" : [ "street_number" ]
},
{
"long_name" : "Carrerasa de la Gallenca",
"short_name" : "Carrerasa de la Gallenca",
"types" : [ "route" ]
},
{
"long_name" : "Castellón de la Plana",
"short_name" : "Castellón de la Plana",
"types" : [ "locality", "political" ]
},
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
},
{
"long_name" : "12004",
"short_name" : "12004",
"types" : [ "postal_code" ]
}
],
"formatted_address" : "Carrerasa de la Gallenca, 31, 12004 Castellón de la Plana, Castellón, España",
"geometry" : {
"location" : {
"lat" : 39.997701,
"lng" : 0.0009023
},
"location_type" : "ROOFTOP",
"viewport" : {
"northeast" : {
"lat" : 39.9990499802915,
"lng" : 0.00225128029150203
},
"southwest" : {
"lat" : 39.9963520197085,
"lng" : -0.0004466802915020301
}
}
},
"place_id" : "ChIJM6FxFAoAoBIRJoJc_bBHm-c",
"types" : [ "street_address" ]
},
{
"address_components" : [
{
"long_name" : "12004",
"short_name" : "12004",
"types" : [ "postal_code" ]
},
{
"long_name" : "Castellón de la Plana",
"short_name" : "Castellón de la Plana",
"types" : [ "locality", "political" ]
},
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "12004 Castellón de la Plana, Castellón, España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 40.06441350000001,
"lng" : 0.0199294
},
"southwest" : {
"lat" : 39.9876763,
"lng" : -0.0908162
}
},
"location" : {
"lat" : 40.0120227,
"lng" : -0.0279867
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 40.06441350000001,
"lng" : 0.0199294
},
"southwest" : {
"lat" : 39.9876763,
"lng" : -0.0908162
}
}
},
"place_id" : "ChIJRxeTAgn_Xw0REF0TPnKvAhw",
"types" : [ "postal_code" ]
}
],
"status" : "OK"
}
A partir de la raíz (que ahora sí es un objeto), tenemos dos miembros: Results y status. Results es un array (un elemento por cada “sitio” encontrado), donde cada elemento, además de información diversa, tiene un miembro que es una pareja clave-valor que nos puede interesar: formatted_address. El otro miembro, status, nos dice cómo ha ido. Cuando no encuentra nada nos lo indica así (https://maps.googleapis.com/maps/api/geocode/json?latlng=40,1 que está dentro del mar):
1
2
3
4
{
"results" : [],
"status" : "ZERO_RESULTS"
}
El formato json es muy utilizado en API’s. La mayoría de webs ofrecen servicios REST para consultar sus bases de datos en este formato.
https://www.sitepoint.com/10-example-json-files/
5.2 Gson
Gson es una biblioteca de código abierto para el lenguaje de programación Java que permite la serialización y deserialización entre objetos Java y su representación en notación JSON.
Para usar esta librería en IntelliJ, debemos importarla desde File->Project Structure y buscar la librería
Pulsar el botón +
Y buscar la librería com.google.code.gson
5.2.1 Deserializando JSON a un objeto Properties
En este primer ejemplo vamos a ver cómo deserializar nuestro objeto JSON en un objeto Properties (Java). Nuestro objeto JSON es el siguiente:
1
2
3
4
5
6
7
{
"num":1,
"nombre": "Andreu",
"departamento": 10,
"edad": 32,
"sueldo": 1000.0
}
Deserializar este objeto en un Properties (java.util.Properties) es muy sencillo con Gson. Basta con crear un objeto Gson e invocar a su método fromJson. Como parámetros le pasaremos el objeto JSON como String y la clase del objeto en que se deserializará:
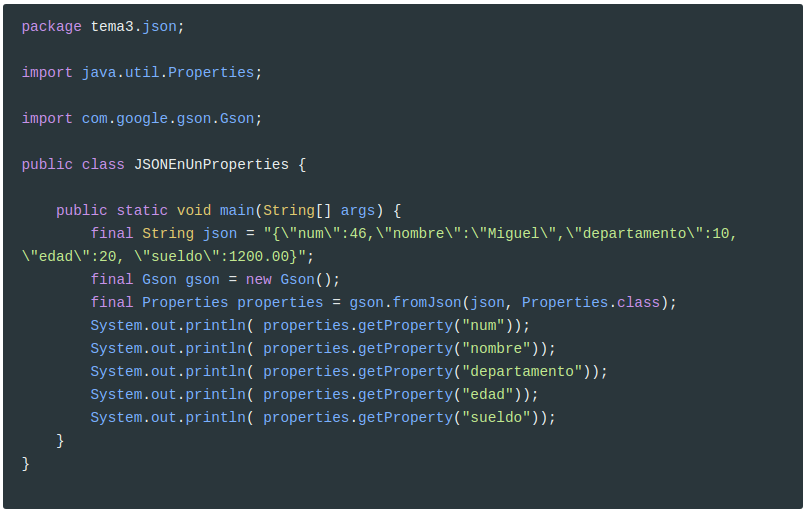
Y esta será la salida:
1
2
3
4
5
46
Miguel
10
20
1200.00
5.2.2 Deserializando JSON a un objeto propio
En este caso vamos a convertir JSON en objetos propios. En este caso la clase Empleado
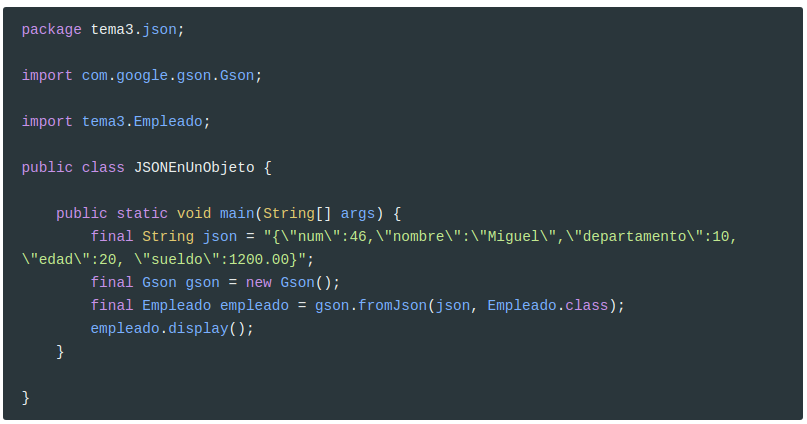
Es igual que el ejemplo anterior pero ahora le pasamos Empleado.class . Así de sencillo.
Y esta es la salida:
1
Num: 46, Nombre: Miguel, Departamento: 10, edad: 20, sueldo:1200.0
5.2.3 Serializando nuestro objeto propio en JSON
En el siguiente ejemplo se muestra cómo convertir un objeto Empleado en su correspondiente notación JSON, usando el método toJson()
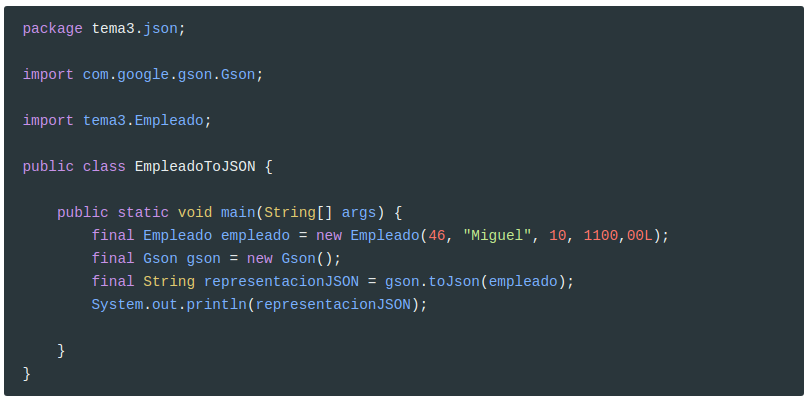
Esta es la salida en formato JSON:
1
{"num":46,"nombre":"Miguel","departamento":10,"edad":1100,"sueldo":0.0}
5.2.4 Serializando nuestro objeto propio en JSON “bonito”.
Al serializar objetos, gson los guarda en un sola línea, por lo que resulta difícil de interpretar los datos. Para mejorar esta representación de debe crear la instancia Gson mediante GsonBuilder que tiene un método (setPrettyPrinting()) y lo activamos mediante el método create().
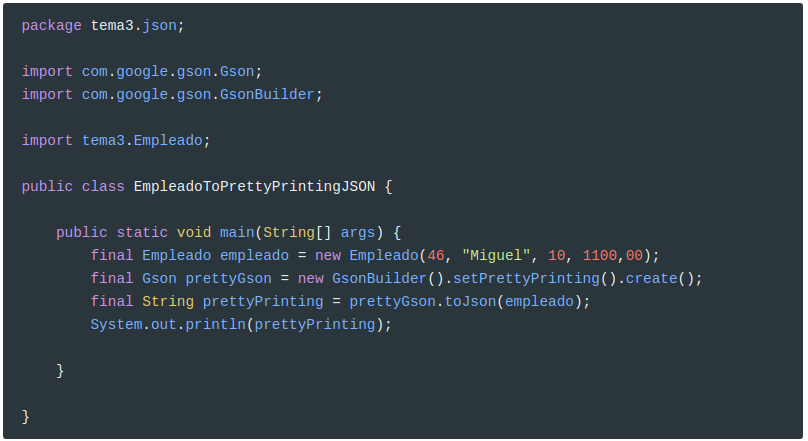
1
2
3
4
5
6
7
{
"num": 46,
"nombre": "Miguel",
"departamento": 10,
"edad": 1100,
"sueldo": 0.0
}
5.2.5 Deserializando una lista de objetos
En los ejemplos anteriores, sólo hemos mapeado un objeto Empleado. Pero también podemos hacer lo mismo con listas de Empleados.
Por ejemplo, partiendo del siguiente json.
1
2
3
4
[
{ "num":1, "nombre": "Andreu", "departamento": 10, "edad": 32, "sueldo": 1000.0},
{ "num":2, "nombre": "Bernat", "departamento": 20, "edad": 28, "sueldo": 1200.0}
]
La única diferencia es que ahora el segundo parámetro del método fromJSON no es la clase a la que queremos deserializar el objeto JSON sino un objeto Type (java.lang.reflect.Type) que habremos creado mediante TypeToken
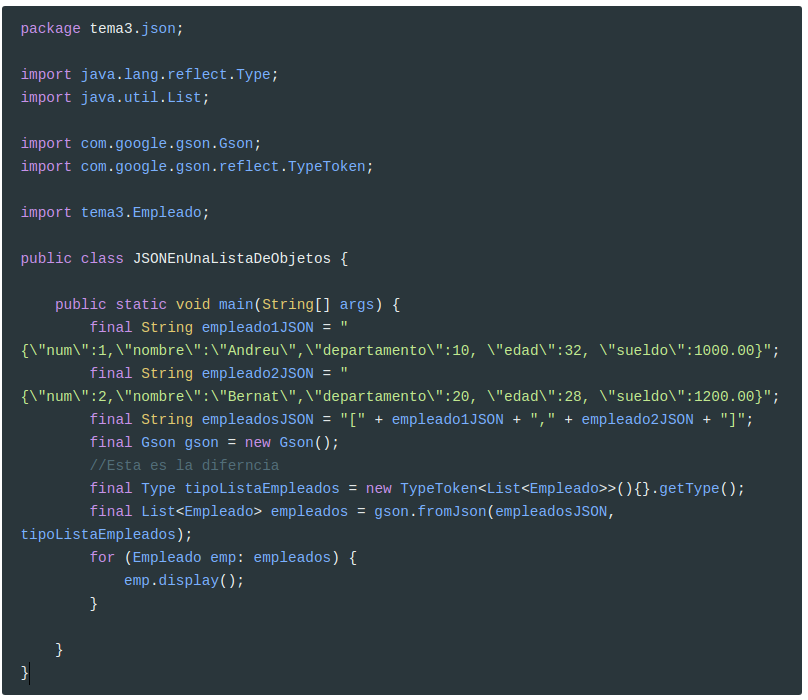
5.2.6 Serializando una lista de objetos
En este caso, hemos de abrir un archivo para escritura con FileWriter y pasárselo como argumento al método toJson()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
package tema3.json;
import java.io.FileWriter;
import java.io.Writer;
import java.lang.reflect.Type;
import java.util.List;
import java.io.IOException;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import tema3.Empleado;
public class EscribirEnFicheroJSON {
public static void main(String[] args) throws IOException{
final String empleado1JSON = "{\"num\":1,\"nombre\":\"Andreu\",\"departamento\":10, \"edad\":32, \"sueldo\":1000.00}";
final String empleado2JSON = "{\"num\":2,\"nombre\":\"Bernat\",\"departamento\":20, \"edad\":28, \"sueldo\":1200.00}";
final String empleadosJSON = "[" + empleado1JSON + "," + empleado2JSON + "]";
final Gson gson = new Gson();
final Type tipoListaEmpleados = new TypeToken<List<Empleado>>(){}.getType();
final List<Empleado> empleados = gson.fromJson(empleadosJSON, tipoListaEmpleados);
final Writer w_json = new FileWriter("./archivos/empleadosdos.json");
final String representacionJSON = gson.toJson(empleados);
w_json.write(representacionJSON);
w_json.close();
}
}
5.2.7 Deserializando objetos más complejos
Gson es una librería para serializar y deserializar objetos. Por tanto, para poder realizar esta transformación hemos de tener implementadas las clases presentes en el fichero json. Vamos a ver un ejemplo más complejo, procesando la respuesta json devuelta desde el api de Google Maps.
Lo más sencillo para crear la clase que mapea los datos devueltos es pasarle a la IA la cadena JSON y pedirle que te la convierta a una clase Gson. No siempre acierta a la primera, pero ya tienes trabajo tedioso hecho
Os dejo un ejemplo de este json devuelto.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
{
"results" : [
{
"address_components" : [
{
"long_name" : "31",
"short_name" : "31",
"types" : [ "street_number" ]
},
{
"long_name" : "Carrerasa de la Gallenca",
"short_name" : "Carrerasa de la Gallenca",
"types" : [ "route" ]
},
{
"long_name" : "Castellón de la Plana",
"short_name" : "Castellón de la Plana",
"types" : [ "locality", "political" ]
},
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
},
{
"long_name" : "12004",
"short_name" : "12004",
"types" : [ "postal_code" ]
}
],
"formatted_address" : "Carrerasa de la Gallenca, 31, 12004 Castellón de la Plana, Castellón, España",
"geometry" : {
"location" : {
"lat" : 39.997701,
"lng" : 0.0009023
},
"location_type" : "ROOFTOP",
"viewport" : {
"northeast" : {
"lat" : 39.9990499802915,
"lng" : 0.00225128029150203
},
"southwest" : {
"lat" : 39.9963520197085,
"lng" : -0.0004466802915020301
}
}
},
"place_id" : "ChIJM6FxFAoAoBIRJoJc_bBHm-c",
"types" : [ "street_address" ]
},
{
"address_components" : [
{
"long_name" : "12004",
"short_name" : "12004",
"types" : [ "postal_code" ]
},
{
"long_name" : "Castellón de la Plana",
"short_name" : "Castellón de la Plana",
"types" : [ "locality", "political" ]
},
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "12004 Castellón de la Plana, Castellón, España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 40.06441350000001,
"lng" : 0.0199294
},
"southwest" : {
"lat" : 39.9876763,
"lng" : -0.0908162
}
},
"location" : {
"lat" : 40.0120227,
"lng" : -0.0279867
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 40.06441350000001,
"lng" : 0.0199294
},
"southwest" : {
"lat" : 39.9876763,
"lng" : -0.0908162
}
}
},
"place_id" : "ChIJRxeTAgn_Xw0REF0TPnKvAhw",
"types" : [ "postal_code" ]
},
{
"address_components" : [
{
"long_name" : "Castellón de la Plana",
"short_name" : "Castellón de la Plana",
"types" : [ "administrative_area_level_4", "political" ]
},
{
"long_name" : "Plana Alta",
"short_name" : "Plana Alta",
"types" : [ "administrative_area_level_3", "political" ]
},
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "Castellón de la Plana, Castellón, España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 40.06441350000001,
"lng" : 0.6912275999999999
},
"southwest" : {
"lat" : 39.8501212,
"lng" : -0.1644067
}
},
"location" : {
"lat" : 40.0017505,
"lng" : -0.05599390000000001
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 40.06441350000001,
"lng" : 0.6912275999999999
},
"southwest" : {
"lat" : 39.8501212,
"lng" : -0.1644067
}
}
},
"place_id" : "ChIJ34vk7yj-Xw0RXqONjd-SdlM",
"types" : [ "administrative_area_level_4", "political" ]
},
{
"address_components" : [
{
"long_name" : "Plana Alta",
"short_name" : "Plana Alta",
"types" : [ "administrative_area_level_3", "political" ]
},
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "Plana Alta, Castellón, España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 40.4182745,
"lng" : 0.6887496
},
"southwest" : {
"lat" : 39.8933317,
"lng" : -0.1659079
}
},
"location" : {
"lat" : 40.2271003,
"lng" : 0.0746767
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 40.4182745,
"lng" : 0.6887496
},
"southwest" : {
"lat" : 39.8933317,
"lng" : -0.1659079
}
}
},
"place_id" : "ChIJHWyn-ncXoBIRxF_Aq-DRWQg",
"types" : [ "administrative_area_level_3", "political" ]
},
{
"address_components" : [
{
"long_name" : "Castellón",
"short_name" : "Castellón",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "Castellón, España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 40.7886312,
"lng" : 0.6912275999999999
},
"southwest" : {
"lat" : 39.7146978,
"lng" : -0.8462968
}
},
"location" : {
"lat" : 40.1451772,
"lng" : -0.1494988
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 40.7886312,
"lng" : 0.6912275999999999
},
"southwest" : {
"lat" : 39.7146978,
"lng" : -0.8462968
}
}
},
"place_id" : "ChIJd-4zz4vzXw0R8Mkh126vAgM",
"types" : [ "administrative_area_level_2", "political" ]
},
{
"address_components" : [
{
"long_name" : "Comunidad Valenciana",
"short_name" : "Comunidad Valenciana",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "Comunidad Valenciana, España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 40.7886312,
"lng" : 0.6912275999999999
},
"southwest" : {
"lat" : 37.8438987,
"lng" : -1.5289447
}
},
"location" : {
"lat" : 39.4840108,
"lng" : -0.7532808999999999
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 40.7886312,
"lng" : 0.6912275999999999
},
"southwest" : {
"lat" : 37.8438987,
"lng" : -1.5289447
}
}
},
"place_id" : "ChIJDTGOzUD8XQ0RXQsxGLjLQF8",
"types" : [ "administrative_area_level_1", "political" ]
},
{
"address_components" : [
{
"long_name" : "España",
"short_name" : "ES",
"types" : [ "country", "political" ]
}
],
"formatted_address" : "España",
"geometry" : {
"bounds" : {
"northeast" : {
"lat" : 43.8504,
"lng" : 4.6362
},
"southwest" : {
"lat" : 27.4985,
"lng" : -18.2648001
}
},
"location" : {
"lat" : 40.46366700000001,
"lng" : -3.74922
},
"location_type" : "APPROXIMATE",
"viewport" : {
"northeast" : {
"lat" : 45.244,
"lng" : 5.098
},
"southwest" : {
"lat" : 35.17300000000001,
"lng" : -12.524
}
}
},
"place_id" : "ChIJi7xhMnjjQgwR7KNoB5Qs7KY",
"types" : [ "country", "political" ]
}
],
"status" : "OK"
}s
Si vemos el archivo json con el navegador
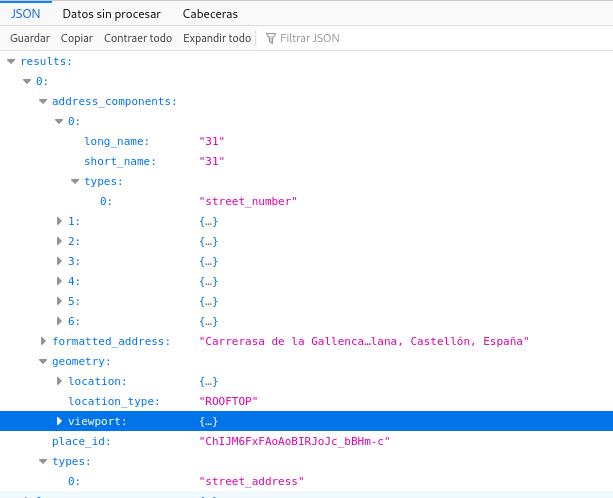
Vemos que cada resultado tiene los siguientes campos:
address_componentsque a su vez es una lista de objetosformated_addresses unStringgeometryes un objeto que a su vez contiene otro objeto para representar la (Latitud, Longitud)place_ides unStringtypeses otra lista deString
Los campos deben escribirse tal cual vienen en el archivo json, a no ser que se anote el campo
La clase AddressComponent queda así:
1
2
3
4
static class AddressComponent {
String long_name, short_name;
List<String> types;
}
Y la clase Geometry, así:
1
2
3
4
5
6
7
8
static class Geometry {
LatLng location;
String location_type;
static class LatLng {
double lat, lng;
}
}
No vamos a mapear todos los datos de la estructura
json
El primer paso es crear una clase que represente esta estructura, donde los resultados se mapean en una lista.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
package googlemaps;
import java.util.List;
public class GeoResponse {
List<Result> results;
String status;
static class Result {
// Esta propiedad es una lista de AddessComponent
List<AddressComponent> address_components;
String formatted_address;
Geometry geometry;
String place_id;
List<String> types;
// Y esta tiene a su vez una lista de String
static class AddressComponent {
String long_name, short_name;
List<String> types;
}
// Y esta tiene una clase LatLng
static class Geometry {
LatLng location;
String location_type;
static class LatLng {
double lat, lng;
}
}
}
}
Una vez tenemos la clase para mapear los objetos json, el código para procesarla es igual de sencillo que para la clase Empleado:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
package googlemaps;
import com.google.gson.*;
import java.io.IOException;
import java.io.InputStream;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class LeerGmaps {
public static void main (String[] args) throws IOException{
final Gson gson = new Gson();
final InputStream f = new FileInputStream("src/main/resources/gmaps.json");
final BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(f));
GeoResponse g = gson.fromJson(bufferedReader, GeoResponse.class);
for (GeoResponse.Result r: g.results ) {
System.out.println(r.formatted_address);
System.out.println("\tLatitud: " + r.geometry.location.lat + " Longitud: " + r.geometry.location.lng);
}
bufferedReader.close();
}
}
Reto 1
Aquí encontrarás la información en formato JSON de la especie pokémon
AegislashA partir de este fichero, debes generar la siguiente salida:
Reto 2
En este reto deberás obtener la información directamente del api de pokémon (sin guardarla en disco)
Por ejemplo para el pokémon ditto la url es https://pokeapi.co/api/v2/pokemon/ditto
Después debes imprimir la siguiente información del pokémon
Reto 3
Antes de escoger una api, preguntadme si cumple los requisitos para usarla
Elige una api de las que se listan en este listado de apis. Elige una cuyo método
Authsea apiKey o No.Después, crea un programa que lea algún dato de esa api y muestre los datos por pantalla.
En el caso de que elijas una de tipo apiKey deberás registrarte en la web para que te den un
client_apiy unclient_secret. Debes conocer el formato de llamada a la api para realizar una petición a la misma por lo que has de consultar su documentación. Con los datos devueltos, debes generar un archivohtmlválido con la información devuelta.Para conseguir el token usa este código:
En el siguiente código tienes un ejemplo de petición a la api de Spotify con el apiKey obtenido antes: