Para escribir sentencias SQL, JDBC dispone de los objetos Statement. Se trata de objetos que se han de crear a partir de Connection, los cuales pueden enviar sentencias SQL al SGBD conectado para que se ejecutan con el método executeQuery o executeUpdate.
Hay una variante del Statement, llamada PreparedStatement que nos da más versatilidad para poner parámetros y ejecutar la sentencia de otro modo. Lo veremos más adelante.
La diferencia entre los dos métodos que ejecutan sentencias SQL es:
- El método
executeQuerysirve para ejecutar sentencias de las que se espera que devuelven datos, es decir, son consultas SELECT. - En cambio, el método
executeUpdatesirve específicamente para sentencias que no devuelven datos. Servirán para modificar la Base de Datos conectada (INSERT, DELETE, UPDATE, incluso CREATE TABLE).
Sentencias que no devuelven datos
Las ejecutamos con el método executeUpdate. Serán todas las sentencias SQL excepto el SELECT, que es la de consulta. Es decir, nos servirá para las siguientes sentencias:
- Sentencias que cambian las estructuras internas de la BD donde se guardan los datos (instrucciones conocidas con las siglas DDL, del inglés Data Definition Language), como por ejemplo
CREATE TABLE,CREATE VIEW,ALTER TABLE,DROP TABLE, …, - Sentencias para otorgar permisos a los usuarios existentes o crear otros nuevos (subgrupo de instrucciones conocidas como DCL o Data Control Language), como por ejemplo
GRANT. - Y también las sentencias para modificar los datos guardados utilizando las instrucciones
INSERT,UPDATEyDELETE.
Aunque se trata de sentencias muy dispares, desde el punto de vista de la comunicación con el SGBD se comportan de manera muy similar, siguiendo el siguiente patrón:
- Instanciación del
Statementa partir de una conexión activa. - Ejecución de una sentencia SQL pasada por parámetro al método
executeUpdate. - Cierre del objeto
Statementinstanciado.
Miremos este ejemplo, en el que vamos a crear una tabla muy sencilla en la Base de Datos MySql/network
Nota En este enlace tenéis la clase DatabaseConnection
1
2
3
4
5
6
7
8
9
public class Main {
static java.sql.Connection con;
public static void main(String[] args) {
String host = "jdbc:sqlite:src/main/resources/network";
con = java.sql.DriverManager.getConnection(host);
// No hace nada, de momento
}
}
Debe aparecer en la consola:
1
Conexión realizada
Sentencias que devuelven datos
Las ejecutamos con el método executeQuery. Servirá para la sentencia SELECT, que es la de consulta.
Los datos que nos devuelva esta sentencia las tendremos que guardar en un objeto de la clase java.sql.ResultSet, es decir conjunto de resultado. Por lo tanto, la ejecución de las consultas tendrá un forma similar a la siguiente:
1
ResultSet rs = st.executeQuery(sentenciaSQL);
El objeto ResultSet contiene el resultado de la consulta organizado por filas, por lo que en cada momento se puede consultar una fila. Para ir visitando todas las filas de una a una, iremos llamando el método next() del objeto ResultSet, ya que cada vez que se ejecute next avanzará a la siguiente fila. Inmediatamente después de una ejecución, el ResultSet se encuentra posicionado justo antes de la primera fila, por lo tanto para acceder a la primera fila será necesario ejecutar next una vez. Cuando las filas se acaban, el método next devolverá falso.
Desde cada fila se podrá acceder al valor de sus columnas con ayuda de varios métodos get disponibles según el tipo de datos a devolver y pasando por parámetro el número de columna que deseamos obtener. El nombre de los métodos comienza por get seguido del nombre del tipo de datos. Así, si queremos recuperar la segunda columna, sabiendo que es un dato de tipo String habrá que ejecutar:
1
rs.getInt(1);
Las columnas se empiezan a contar a partir del valor 1 (no cero). La mayor parte de los SGDB soportan la posibilidad de pasar por parámetro el nombre de la columna, pero no todos, así que normalmente se opta por el parámetro numérico.
Por ejemplo MySql sí que deja acceder por nombre, por tanto, suponiendo que el campo 1 se llama ID, también se puede hacer:
1
rs.getInt("ID");
En este ejemplo accedemos a la tabla usuarios y mostramos todos sus registros
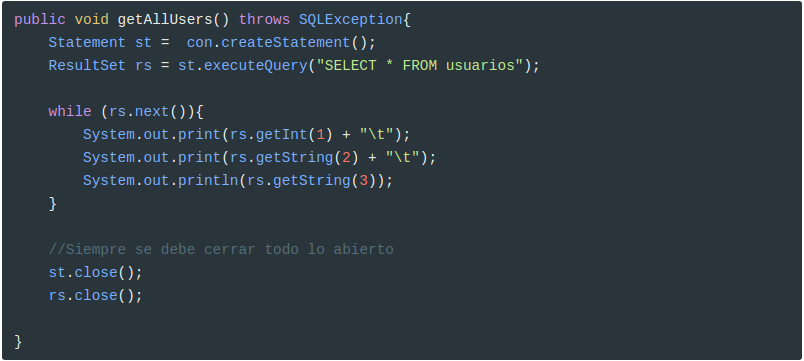
Asegurar la liberación de recursos
Las instancias de Connection y las de Statement guardan, en memoria, mucha información relacionada con las ejecuciones realizadas. Además, mientras continúan activas mantienen en el SGBD una sesión abierta, que supondrá un conjunto importante de recursos abiertos, destinados a servir de forma eficiente las peticiones de los clientes. Es importante cerrar estos objetos para liberar recursos tanto del cliente como del servidor.
Si en un mismo método debemos cerrar un objeto Statement y el Connection a partir del cual la hemos creado, se deberá cerrar primero el Statement y después el Connection. Si lo hacemos al revés, cuando intentamos cerrar el Statement nos saltará una excepción de tipo SQLException, ya que el cierre de la conexión le habría dejado inaccesible.
Además de respetar el orden, asegurar la liberación de los recursos situando las operaciones de cierre dentro de un bloque finally. De este modo, aunque se produzcan errores, no se dejarán de ejecutar las instrucciones de cierre.
Hay que tener en cuenta todavía un detalle más cuando sea necesario realizar el cierre de varios objetos a la vez. En este caso, aunque las situamos una tras otra, todas las instrucciones de cierre dentro del bloque finally, no sería suficiente garantía para asegurar la ejecución de todos los cierres, ya que, si mientras se produce el cierre de un los objetos se lanza una excepción, los objetos invocados en una posición posterior a la del que se ha producido el error no se cerrarán.
La solución de este problema pasa por evitar el lanzamiento de cualquier excepción durante el proceso de cierre. Una posible forma es encapsular cada cierre entre sentencias try-catch dentro del finally
Aquí tenéis un ejemplo completo:
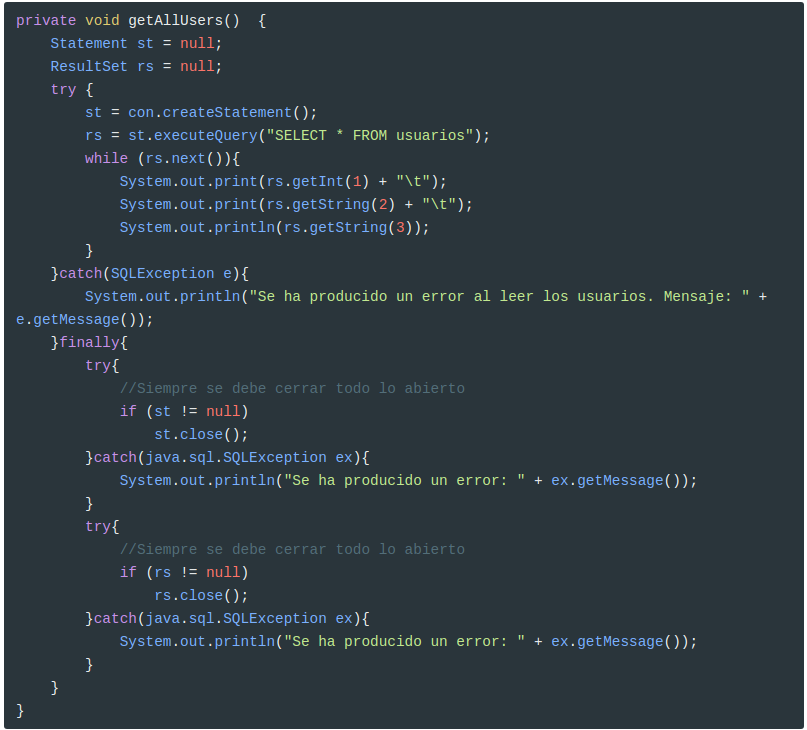
Nosotros obviaremos la gestión de errores con el fin de acortar los programas:
Sentencias predefinidas
Para solucionar el problema de crear sentencias sql complejas, se utiliza PreparedStatement.
JDBC dispone de un objeto derivado del Statement que se llama PreparedStatement, al que se le pasa la sentencia SQL en el momento de crearlo, no en el momento de ejecutar la sentencia (como pasaba con Statement). Y además esta sentencia puede admitir parámetros, lo que nos puede ir muy bien en determinadas ocasiones.
De cualquier modo, PreparedStatement presenta ventajas sobre su antecesor Statement cuando nos toque trabajar con sentencias que se hayan de ejecutar varias veces. La razón es que cualquier sentencia SQL, cuando se envía al SGBD será compilada antes de ser ejecutada.
- Utilizando un objeto
Statement, cada vez que hacemos una ejecución de una sentencia, ya sea víaexecuteUpdateo bien víaexecuteQuery, el SGBD la compilará, ya que le llegará en forma de cadena de caracteres. - En cambio, al
PreparedStamentla sentencia nunca varía y por lo tanto se puede compilar y guardar dentro del mismo objeto, por lo que las siguientes veces que se ejecute no habrá que compilarse. Esto reducirá sensiblemente el tiempo de ejecución.
En algunos sistemas gestores, además, usar PreparedStatements puede llegar a suponer más ventajas, ya que utilizan la secuencia de bytes de la sentencia para detectar si se trata de una sentencia nueva o ya se ha servido con anterioridad. De esta manera se propicia que el sistema guarde las respuestas en la memoria caché, de manera que se puedan entregar de forma más rápida.
La principal diferencia de los objetos PreparedStatement en relación a los Statement, es que en los primeros se les pasa la sentencia SQL predefinida en el momento de crearlo. Como la sentencia queda predefinida, ni los métodos executeUpdate ni executeQuery requerirán ningún parámetro. Es decir, justo al revés que en el Statement.
Los parámetros de la sentencia se marcarán con el símbolo de interrogación (?) Y se identificarán por la posición que ocupan en la sentencia, empezando a contar desde la izquierda a partir del número 1. El valor de los parámetros se asignará utilizando el método específico, de acuerdo con el tipo de datos a asignar. El nombre empezará por set y continuará con el nombre del tipo de datos (ejemplos: setString, setInt, setLong, setBoolean …). Todos estos métodos siguen la misma sintaxis:
1
setXXXX(<posiciónEnLaSentenciaSQL>, <valor>);
Trabajar con Sqlite
Para poder trabajar en casa, vamos a utilizar Sqlite que es un una base de datos sencilla que se guarda en un único archivo en disco.
Esta base de datos es la más usada en el mundo pues todos los móviles Android la llevan incorporada
Lo primero es instalar SQLite, en Ubuntu
1
sudo apt-get install sqlite
Si queréis hacerlo en Windows, podéis seguir las instrucciones en http://www.sqlitetutorial.net/download-install-sqlite/
Lo primero que hemos de hacer es crear una base de datos, desde la línea de comandos. Para ello nos situamos en el directorio del proyecto y la creamos en el directorio bd mediante el siguiente comando:
1
2
3
4
5
cd directorio-de-recursos-del-proyecto
sqlite3 empresa.bd
Enter ".help" for usage hints.
sqlite> SELECT name FROM sqlite_master WHERE type='table';
sqlite> .quit
Comprueba que realmente se ha creado la base de datos (aunque también veremos que se puede crear desde IntelliJ)
Mediante estos comandos creamos una base de datos en disco llamada empresa.bd.
Para continuar en IntelliJ, hemos de importar la dependencia
1
2
3
4
5
6
7
8
<!-- https://mvnrepository.com/artifact/org.xerial/sqlite-jdbc -->
<!-- Source: https://mvnrepository.com/artifact/org.xerial/sqlite-jdbc -->
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.51.1.0</version>
<scope>compile</scope>
</dependency>
Y ahora creamos la clase DatabaseConnection para conectarnos:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import java.sql.Connection;
import java.sql.DriverManager;
public class DatabaseConnection
{
private static Connection con;
public static Connection getConnection(){
try {
// Poned la ruta correcta, de lo contrario, os creará un a bd nueva
String host = "jdbc:sqlite:src/main/resources/empresa.bd";
con = DriverManager.getConnection(host);
System.out.println("Conexión realizada");
} catch (java.sql.SQLException ex) {
System.out.println("Se ha producido un error al conectar: " + ex.getMessage());
}
return con;
}
}
Y lo probamos en un main
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Main {
// Es static porque pertenece a toda la clase y final porque no se va a modificar
static final java.sql.Connection con = conectar();
private static void conectar() throws SQLException {
String host = "jdbc:sqlite:src/main/resources/network";
con = java.sql.DriverManager.getConnection( host);
System.out.println("Conexión realizada");
}
public static void main(String[] args) {
conectar();
// No hace nada, de momento.
// En cada método que creemos, usaremos la variable `con`
}
}
Debe aparecer en la consola el texto:
1
Conexión realizada
En IntelliJ Ultimate aparece un botón  en la parte derecha de la ventana que es un gestor incorporado de bases de datos.
en la parte derecha de la ventana que es un gestor incorporado de bases de datos.
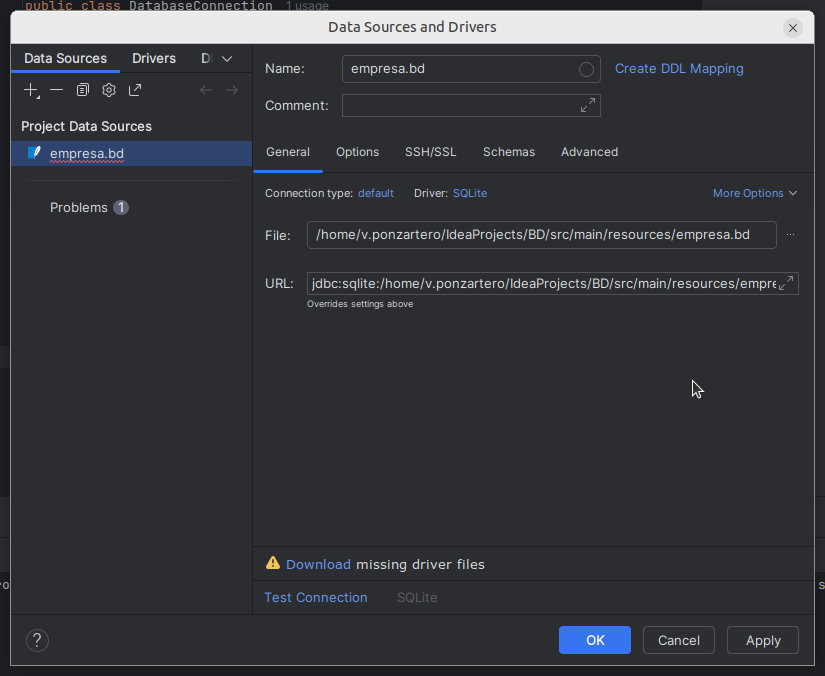
Al hacer clic, se muestra esta ventana:
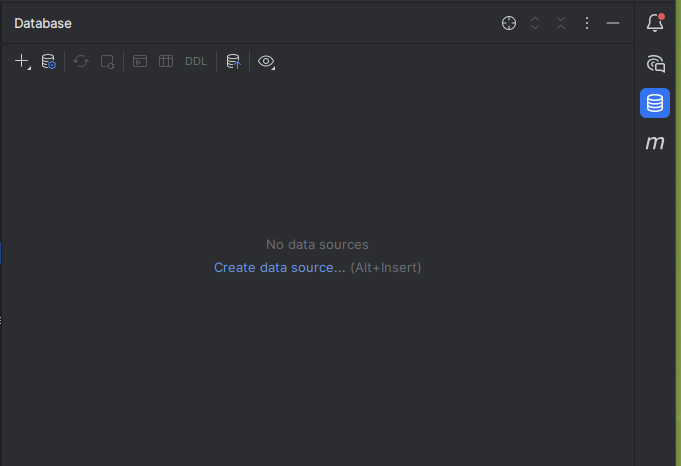
Y podemos dar al + o a Create data source... y buscáis sqlite
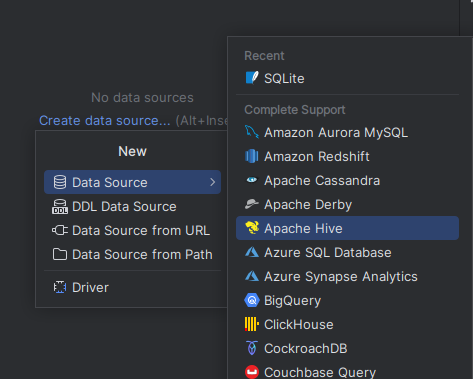
Ahora seleccionamos el archivo de la base de datos empresa.db
Ejemplos
Vamos a crear una pequeña base de datos para Empleados en Sqlite. Elige New -> Query console
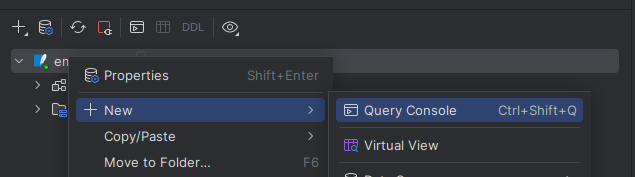
Y pega el siguiente SQL
1
2
3
4
5
6
7
CREATE TABLE empleados (
num INTEGER PRIMARY KEY,
nombre TEXT NOT NULL,
departamento INTEGER NOT NULL,
edad INTEGER CHECK (edad >= 0),
sueldo REAL CHECK (sueldo >= 0)
);
Ahora haz clic en el botón verde con forma de flecha.
Y ahora insertamos los datos:
1
2
3
4
5
INSERT INTO empleados (num, nombre, departamento, edad, sueldo) VALUES
(1, 'Andreu', 10, 32, 1000.00),
(2, 'Bernat', 20, 28, 1200.00),
(3, 'Claudia', 10, 26, 1100.00),
(4, 'Damià', 10, 40, 1500.00);
Insertar datos
Creamos el SQL para insertar mediante preparedStatement y excuteUpdate
Cuando trabajemos con datos sobre los que no tenemos ninguna forma de controlar su contenido, por ejemplo, datos enviados mediante un formulario web, hemos de usar
PreparedStatementpara evitar ataques de inyección de SQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public static void insertarEmpleado(int numero, String nombre, int departamento, int edad, float sueldo) throws SQLException {
// Creamos el SQL. En cada dato ponemos un ?
String sql = "INSERT INTO empleados (num, nombre, departamento, edad, sueldo)";
sql += " VAlUES(?, ?, ?, ?, ?)";
// Preparamos el SQL
PreparedStatement st = con.prepareStatement(sql);
// Y ahora hemos de rellenar los datos, teniendo cuidado de que los tipos
// de la tabla coincidan con el tipo de setter;
st.setInt(1, numero);
st.setString(2, nombre);
st.setInt(3, departamento);
st.setInt(4, edad);
st.setFloat(5, sueldo);
// Y no nos olvidemos de hacer executeUpdate();
st.executeUpdate();
// Imprimimos para ver los resultados
imprimirEmpleados();
}
Ahora llama a este método desde la clase principal.
Consultar datos
Creamos el métido imprimirEmpleados que nos devuelva todos los empleados:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static void imprimirEmpleados() throws SQLException {
// Como no va a tener parámetros, no hace falta crear preparedStatement
Statement st = con.createStatement();
// Creamos el SQL que al ser de consulta se hace con executeQuery()
ResultSet rs = st.executeQuery("SELECT * FROM empleados");
System.out.println("Núm.\tNombre\tDepartamento\tEdad\t Sueldo");
// Y ahora recorremos los datos
while (rs.next()){
// Hemos de hacer coincidir el tipo de getter con
// el tipo de dato de la tabla
System.out.print(rs.getInt(1) + "\t");
System.out.print(rs.getString(2) + "\t");
System.out.print(rs.getInt(3) + "\t");
System.out.print(rs.getInt(4) + "\t");
System.out.println(rs.getFloat(5) + "\t");
}
}
También llama a este método desde el programa principal.
Modificar datos
Ahora modificamos los datos. Por ejemplo, aumentamos el sueldo un 5% y modificamos el departamento del empleado 3 actualizándolo al departamento 20.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private static void actualizarEmpleados() throws SQLException {
// Como no va a tener parámetros, no hace falta crear preparedStatement
// Cuando los datos vengan de fuera de la aplicación, por ejemplo, un
// usuario de una web que envía datos, es OBLIGADO crear un preparedStatement
// para evitar ataques de inyección de SQL
Statement st = con.createStatement();
// Creamos el SQL que al ser de modificación de datos se hace con executeUpdate()
String sql = "UPDATE empleados set sueldo = sueldo * 1.05";
st.executeUpdate(sql);
sql = "UPDATE empleados set departamento = 20 WHERE num = 3";
st.executeUpdate(sql);
}
Y, por último, llama a este método desde la clase principal.
Ejercicio
Crea una aplicación que nos permita gestionar la base de datos network.
Debe tener un menú desde el que se puedan gestionar las operaciones CRUD (Create, Read, Update, Delete) usuarios, posts y comentarios.
Os podéis descargar un esqueleto de la aplicación junto con la clase AnsiColor